海外本地办公区访问高唐机房性能优化方案
一. 背景
1.1 业务背景介绍
2022年11月,Infra对外提供了海外办公网络环境,以及通过ITVPN的海外接入点,让西雅图当地的自营员工访问高唐机房的能力。
但在实际使用访问过程中,G108na测试发现,从西雅图本地通过VPN访问高唐机房时,带宽性能十分有限,而在Oregon本地部署proxy做高唐服务的代理后,从西雅图本地通过VPN发起请求时,带宽性能有了非常大的提升。
基于此情况,我们进行了进一步分析并提供对此现象的优化方案。
1.2 优化方案结论
- 在长肥管道+弱网条件下,tcp的传统拥塞控制算法会导致吞吐利用率极其低下,使用google提供的BBR拥塞控制算法能有效缓解这一问题。
- 基于此实验与收集到的信息可得出结论:
- 在下载场景下,与客户端建立TCP连接的服务器开启BBR是必要的,实际上经过不稳定长肥管道建立tcp的两端,都建议尽量开启BBR。
- 若后端服务器与代理之间链路性能稳定,则后端服务器开不开BBR都无所谓。
- NLB的本质是三层转发,并不缩短TCP连接的延迟,故对吞吐的优化不起到作用。
- AWS的ALB目前不支持开启BBR,且其仅支持http协议端口,故对场景不具备普适性。
- 考虑到客户端并不都支持打开BBR,故最佳实践为:
- 在临近用户侧,且与后端服务端之间不存在弱网连接(比如基于自有物理核心网的纯内网环境)的地方,创建代理服务器。
- 代理服务器开启BBR。
二. 模拟测试
2.1 环境介绍
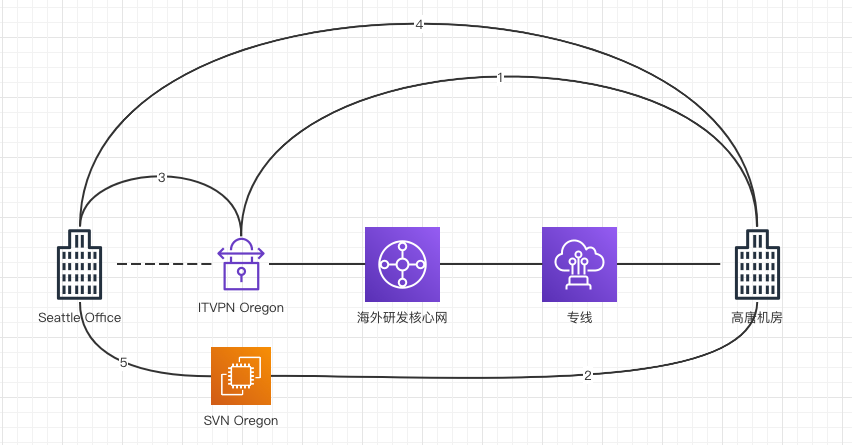
目前从西雅图访问高唐机房的链路,可简化为如下图示:西雅图办公区用户,通过拨通ITVPN连接至Oregon的ITVPN服务端,并通过海外核心网走物理专线至高唐机房。

2.2 实验记录
为了定位在链路传输的过程中,是哪一段造成了信道性能的衰减,做如下对照测试,并记录数据如下:
1. VPN节点-> 高唐物理机 带宽约400Mbit/s
2. SVN节点-> 高唐物理机 带宽约400Mbit/s
3. 西雅图本地 -> VPN隧道 -> VPN节点 带宽约 400Mbit/s
4. 西雅图本地 -> VPN隧道 -> 高唐物理机 带宽约 40Mbit/s
5. 西雅图本地 -> VPN隧道 -> SVN海外研发节点 带宽约 400Mbit/s
2.3 现象描述
从实验中可知:
* 无论是从Oregon到高唐机房(1/2),还是从Seattle访问Oregon(3/5),其带宽性能均非常好,不存在带宽瓶颈。
* 而实际跑TCP业务的时候则会发现性能衰减至1/10,衰减90%。这个现象本身非常诡异。
故需要对此现象进行深入分析讨论。
三. 问题分析
3.1 场景联想
实际上,这不是我们第一次遇到类似的问题,之前在与IT合作的过程中,日本涉谷地区的本地办公区通过meraki与核心网构建ipsec信道之后,TCP业务访问回国的带宽性能就一直上不去,而当时IGI大佬给出的结论是因为丢包造成了重传,导致信道拥塞,开启BBR之后整体性能有了很大的优化。
这个场景其实与当时的场景十分类似,所以我们将注意力集中在了是否是TCP业务缺乏合理的拥塞控制,造成了这一问题上。
而实际上,根据一些弱网条件下,TCP的性能测试报告,也佐证了这一现象并不是孤例:

3.2 TCP协议的性能问题
3.2.1 拥塞控制
- 网络吞吐与信道负荷有着密切的关系,带宽与最小时延是一对互斥的命题,链路带宽塞满时,时延不一定是最优的,而链路过于空的时候,时延才是最优的。当信道中正在传输的数据量超过信道可缓存的数据量,则会出现拥塞现象,从而使网络分片不得不进行重传,导致无意义重传对网络吞吐大量占用,最终带宽利用率变低甚至出现网络死锁。而为了解决这一问题,拥塞控制算法应运而生。其根本出发点为,通过控制发包节奏,在链路正常时递增传包,当出现拥塞时缩小单位时间的发包量。
- 针对拥塞控制,其逻辑为:
- 发送端会维护一个拥塞窗口(cwnd),其大小取决于网络拥塞程度并动态变化(与丢包率相关),为了防止cwnd过大导致拥塞,需要设置一个门限ssthresh。
- 而双方同样也会维护一个接收窗口(rwnd)。
- 客户端可以传输的最大数据段是这二者中的最小值。
- 而拥塞窗口的工作原理满足如下两个特点:
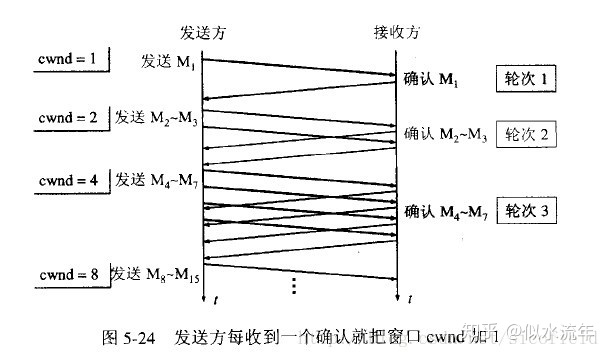
- 慢启动:
- cwnd从小到大增长,当收到上一次确认后,下一次的cwnd才会在上一次的窗口的基础上进行增长。
- 这样拥塞窗口会按照线性规律缓慢增长。
- 慢启动:
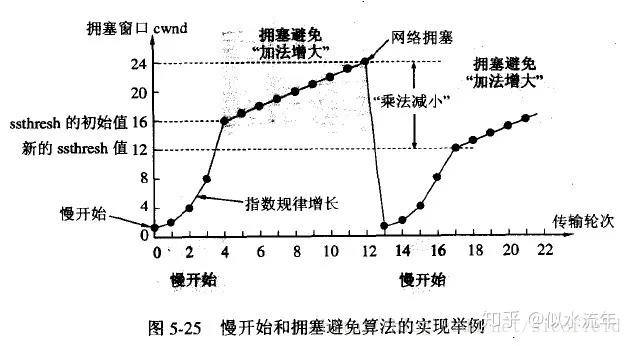
- 拥塞避免算法
- 只要发送方判断出现网络拥塞(没有按RTO收到接收方的确认信息),就会把满开始的门限设置为此时发送窗口的一半(ssthresh=cwnp/2),且在没有启动快恢复时,把拥塞窗口设置为1,重新开始执行慢启动。
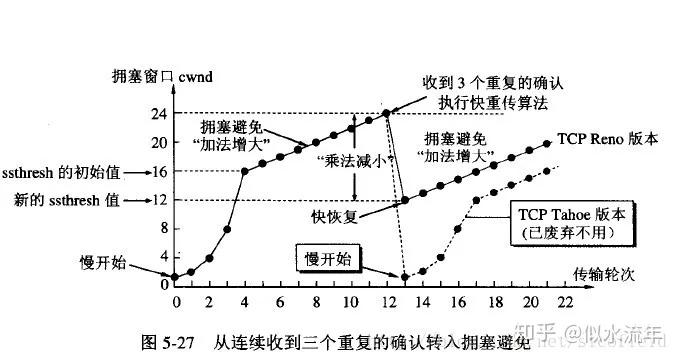
- 快重传与快恢复
- TCP判断,当发送方连续收到三个重复的确认报文时,则会执行快速重传,重新从接收方未传输的报文开始进行重新传输。
- 此时若开启了快恢复,因为连续收到了三个重复的确认报文,则此时并不执行慢开始算法,而是执行拥塞避免算法,让cwnd缓慢增大。
早期的互联网设计是基于短途局域有线网络来构建的,其出现网络不稳定的情况比较低,同时信道对报文的缓存能力十分有限,这导致TCP协议判断出现丢包意味着拥塞,客户端就会开始进行拥塞避免算法,将拥塞窗口进行腰斩,从而缩小单位时间传输的数据量。
3.2.3 BDP与长肥管道
通过上面的分析我们可以知道,传统的拥塞控制算法,是基于小缓存、高质量的信道模型的。它可以有效避免在这类信道中信道缓存被打满而导致的拥塞。
但实际上,现在的通信系统规模变大了,特别是长距离公网通信不可能不面对丢包以及延迟抖动,不能说出现这种现象就判断信道拥塞了。而信道的缓存能力本身也有了质的提升(带宽变大+传输距离变长)。使用老的拥塞算法太过于谨慎会导致误判,带宽利用率上不去。(想深入可具体了解一下浅缓存与深缓存)
为了解决这个问题,现在的算法例如BBR均基于BDP进行拥塞控制。
BDP是用来评判在信道中已传输但尚未被确认的数据量的指标,是作为拥塞避免算法检测机制的重要指标,其计算公式为:信道带宽*延迟。
高BDP的网络被称为长肥网络,理想的长肥网络可以提供更大的接受窗口大小。但实际上,在网络丢包的环境下,因为TCP是基于ACK反馈驱动的,其对链路的感知与响应时间,是正比与RTT的。
在BDP比较小的链路中,基于丢包感知拥塞算法是更优解的:
- 因为链路本身没有什么缓存能力,不会因为发包太猛造成链路缓存都被占满。
- RTO变化不大,按照拥塞窗口进行发包,很快就能在非常短的时间内从最小拥塞窗口通过慢启动达到合适的窗口大小,带宽利用率可以被充分利用。
- 一个比较具体的量化是,即使在目前的信道下,在10ms环境中,窗口大小若为500KB,则信道可用带宽也可达到500*8/0.01/1024=390.625Mbps
而这些对长肥管道而言意味着,会出现严重的浅缓存问题:
- 数据还没有到达接收方,信道缓存还没被充分利用,但是发送方已经受限于窗口大小无法再继续发包了,在我们目前的专线条件下(10Gbps/150ms),BDP的实际大小为10*1024*0.15,约1.5Gbits。
- 而实际上如果因为丢包造成拥塞窗口较小例如900KB,则可用带宽仅为:900*8/0.15/1024=46.875Mbps。
- 而稳定窗口大小要求极低的丢包率,根据相关资料提供的数据,即使在10Gbps/100ms的信道中,丢包率为1%时,其只能维持3Mbps/100ms的传输性能。而要维持这个信道的可用,丢包率需要维持在0.000003%以下。这放在有公网的场景下基本不可接受。
- 其对网络的响应更加滞后,因为RTT长,所以RTO更长。
- 其收敛更慢,因为慢启动会消耗更长的时间(单次进行慢启动算法的时间需要几个RTT)。
- 而消耗的时间更长,意味着丢包的概率越大,从最小窗口到带宽利用率达到最大的过程中,被判断拥塞的概率更大。
- 故链路抖动丢包时,拥塞窗口会急剧下降导致带宽利用率无法上升。
3.2.4 其他TCP协议的性能影响因素
除了上述拥塞算法在丢包大延迟的场景下会造成性能劣化外,三次握手的开销(至少1.5个RTT的网络延时)以及重传造成的带宽占用均会造成性能的损耗,且这种损耗会随着丢包率的上升而指数性上升。基于此次我们遇到的问题的变量并不符合这两种额外开销造成的性能劣化,在此不做赘述。
3.3 BBR拥塞控制算法
基于3.2.3分析的场景,Google的工程师敏锐地发现了这一问题,他们发现当时在网络上使用的TCP依然是基于1980年代创立的cubic拥塞控制算法,而这明显已经不满足目前的网络需求了。故在2016年,他们发表了论文《BBR: Congestion-Based Congestion Control》,并通过这种更为激进的拥塞控制算法,彻底变革了TCP流量在网络上进行传输的方式。
他们通过RTT以及瓶颈传输带宽(一条多跳链路上最小的传输带宽,例如10Gbps-1Gbps-20Gbps信道,带宽瓶颈为1Gbps)来衡量传输性能。其整体逻辑服务于一个基本想法:达到最大瓶颈吞吐的同时,维持传输的最小延迟。其满足于两个基本机制:
- 速率均衡:尽量让数据的到达速率,等于flow的瓶颈带宽,BBR通过pacing让数据包以接近瓶颈带宽的速率进行发送。
- 管道满载:在发送的同时,通过对pacing rate的调节,来确保传输数据量接近BDP,从而保障信道在不拥塞的条件下能够被充分利用。
四. 现象论证
4.1 原实验分析
根据如上分析,我们可以预估出,若对2.2部分的实验进行deep dive,应该会得到如下结论:
实验一:内网传输,无丢包,高延迟,拥塞窗口足够大,带宽大
实验二:内网传输,无丢包,高延迟,拥塞窗口足够大,带宽大
实验三:外网传输,有丢包,拥塞窗口小,低延迟,可用信道带宽大,带宽利用率高
实验四:内外网传输,有丢包,拥塞窗口小,高延迟,可用信道带宽小,带宽利用率低
实验五:内外网传输,有丢包,拥塞窗口小,低延迟,可用信道带宽大,带宽利用率高
而实验四会有很明显的传输等待现象(接收方还没有收到数据,发送方已经暂停数据传输了)。
4.2 实验现象论证
实际抓包后得出的结论如下:
1. VPN节点-> 高唐物理机 带宽约400Mbit/s 窗口约16MBytes
2. SVN节点-> 高唐物理机 带宽约400Mbit/s 窗口约8MBytes
3. 西雅图本地 -> VPN隧道 -> VPN节点 带宽约 350Mbit/s 窗口约500KBytes
4. 西雅图本地 -> VPN隧道 -> 高唐物理机 带宽约 40Mbit/s 窗口约900KBytes BBR后升到 150Mbits 窗口8MBytes
5. 西雅图本地 -> VPN隧道 -> SVN海外研发节点 带宽约 400Mbit/s 窗口约500KBytes
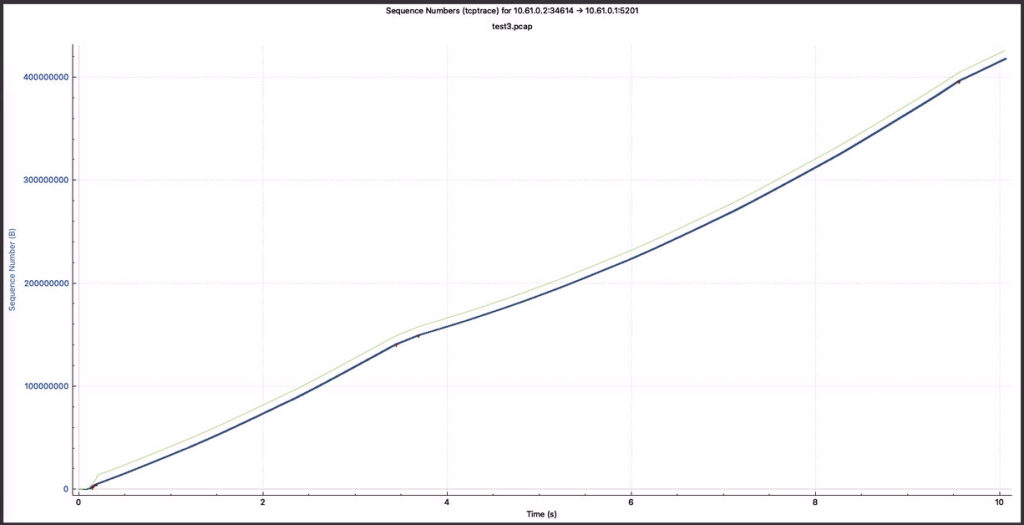
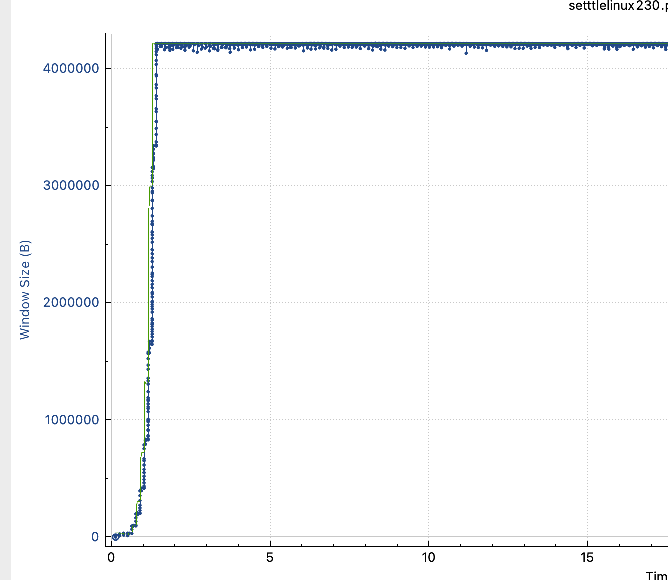
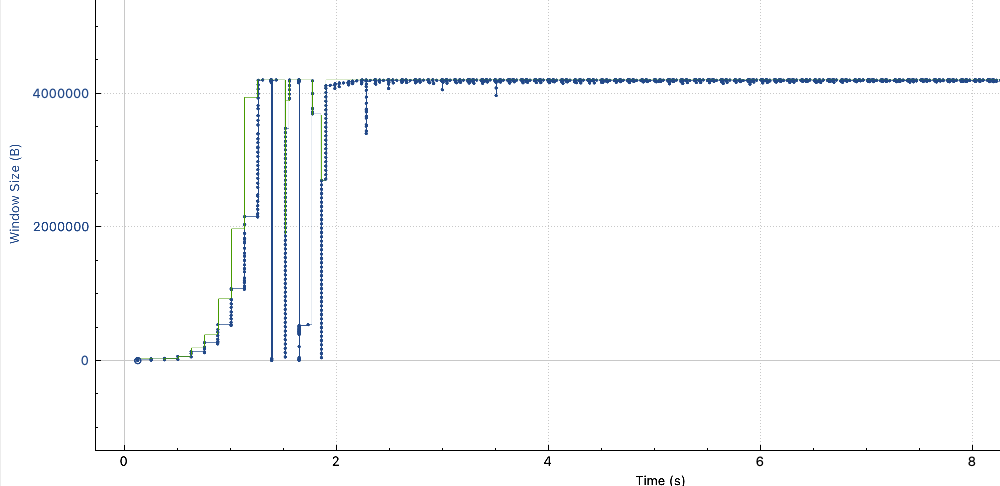
实验2与试验4的窗口大小抓包绘图如下所示:
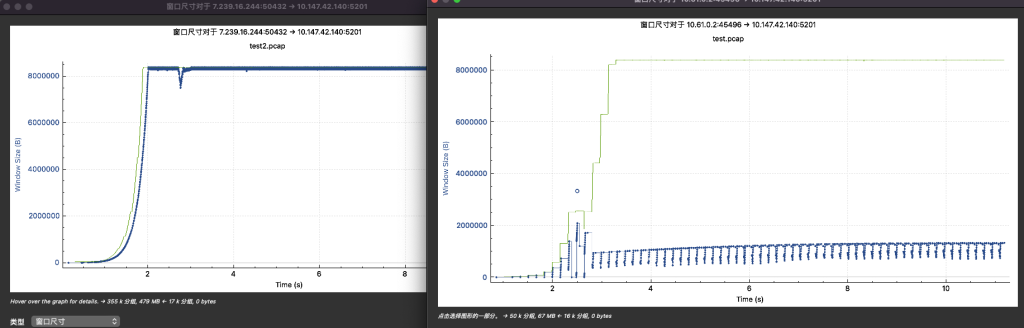
如上结论符合预测预期。
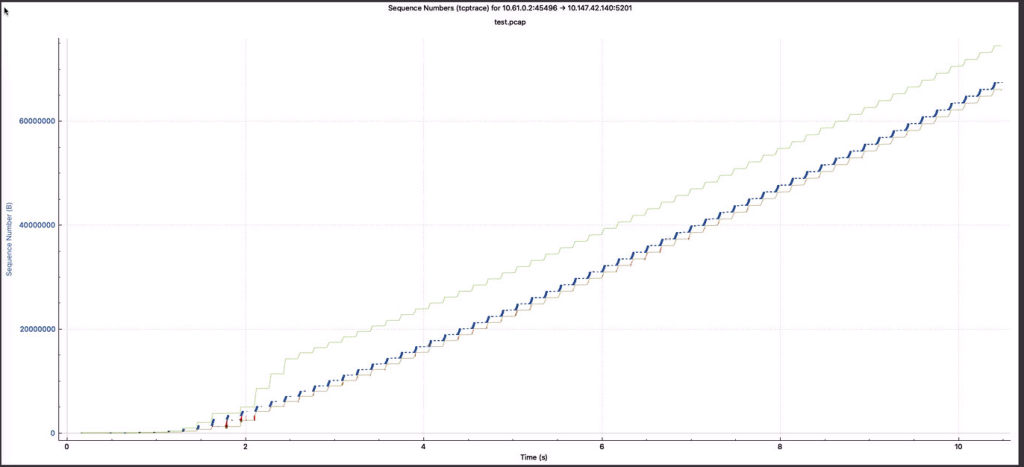
实验四:西雅图->VPN隧道->高唐物理机,无BBR
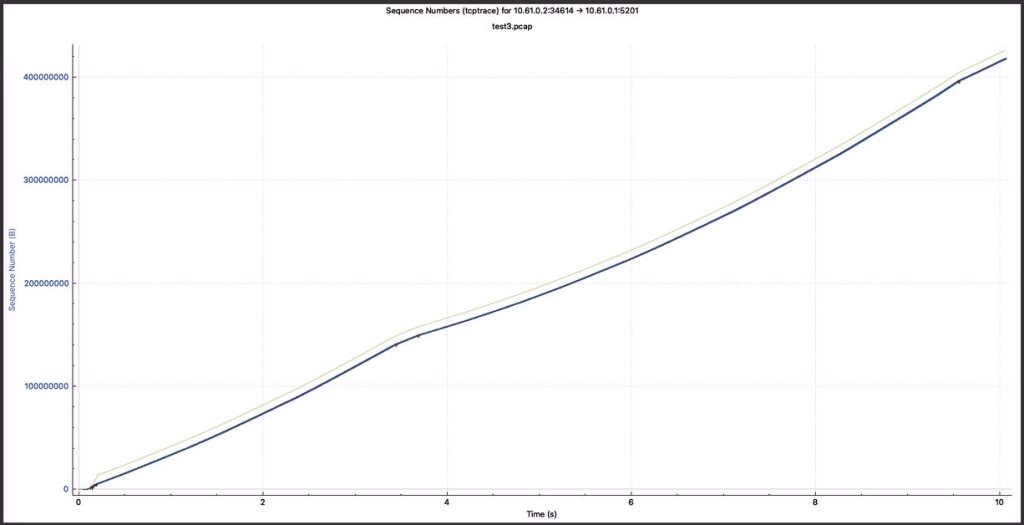
实验五:西雅图->VPN隧道->VPN节点,无BBR
五. 业务模拟
5.1 实际线上业务模拟测试
为了对比测试实际业务网络在使用过程中的吞吐情况,计划进行如下测试并进行分析(场景上,IDC与研发链路上稍有差异,但从分析的角度可以说明问题)
* 下载10GB大文件时的表现
| 客户端 | 服务端 | 加速方式 | 吞吐 | |
| 1 | 西雅图PC | 杭州IDC | 直连 | 2.44MB/s |
| 2 | 西雅图PC | 杭州IDC | 直连+BBR | 14.6MB/s |
| 3 | 西雅图PC | 杭州IDC | Nginx | 2.29MB/s |
| 4 | 西雅图PC | 杭州IDC | Nginx+服务端BBR | 1.19MB/s |
| 5 | Oregon服务器 | 杭州IDC | 直连 | 31.7 MB/s |
| 6 | Oregon服务器 | 杭州IDC | 直连+BBR | 30.3 MB/s |
| 7 | Oregon服务器 | 杭州IDC | Nginx | 31.7MB |
| 8 | 杭州办公区 | 杭州IDC | 直连 | 12.5 MB/s |
| 9 | 杭州办公区 | 杭州IDC | 直连+BBR | 17.4 MB/s |
5.2 详细分析
- 这里值得研究的是3与6这一组数据,在服务端没有开启BBR,西雅图创建nginx之后,长肥管道问题应该是已经被nginx解决了,但:
- 可以看到分段大小非常不稳定,吞吐也相对波动更频繁
- 而从Oregon这里去访问的时候,吞吐又是正常的,分片也相对比较正常
- 将如上两种情况分别分类为A与B,A情况下,服务端的抓包情况如下:
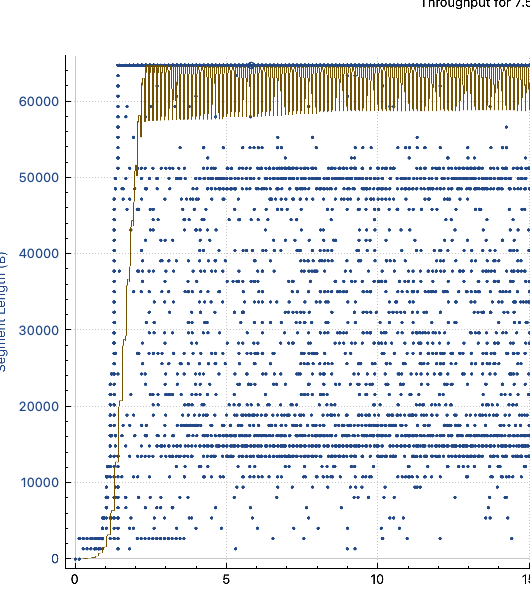
- B情况下,服务端抓包如下:
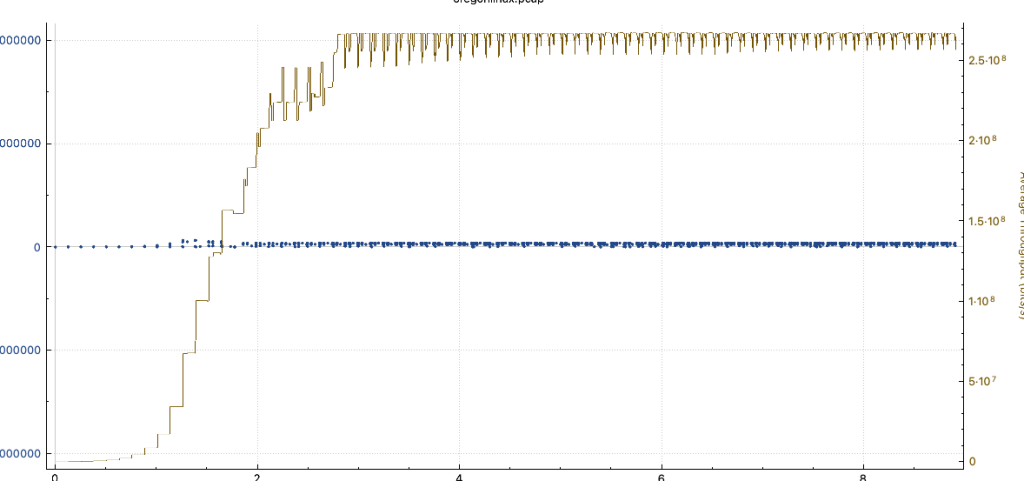
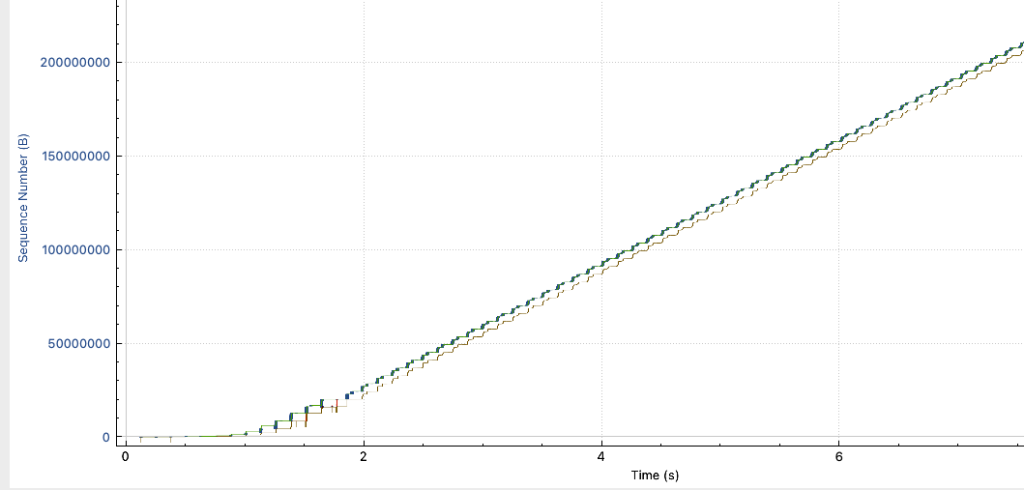
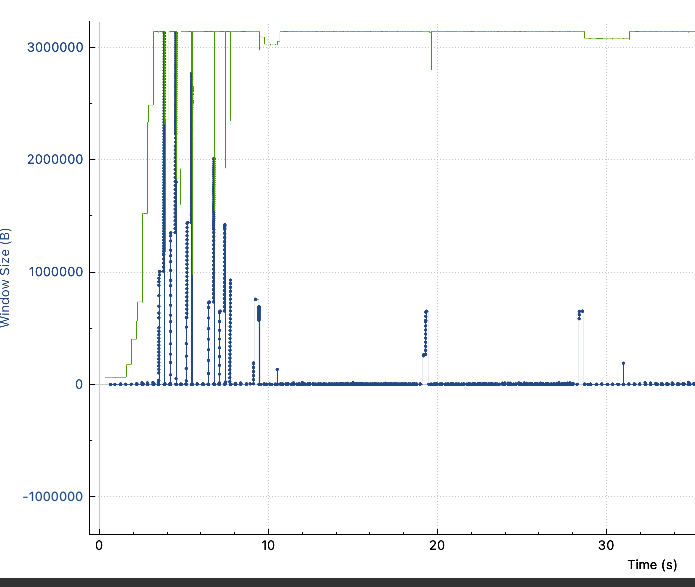
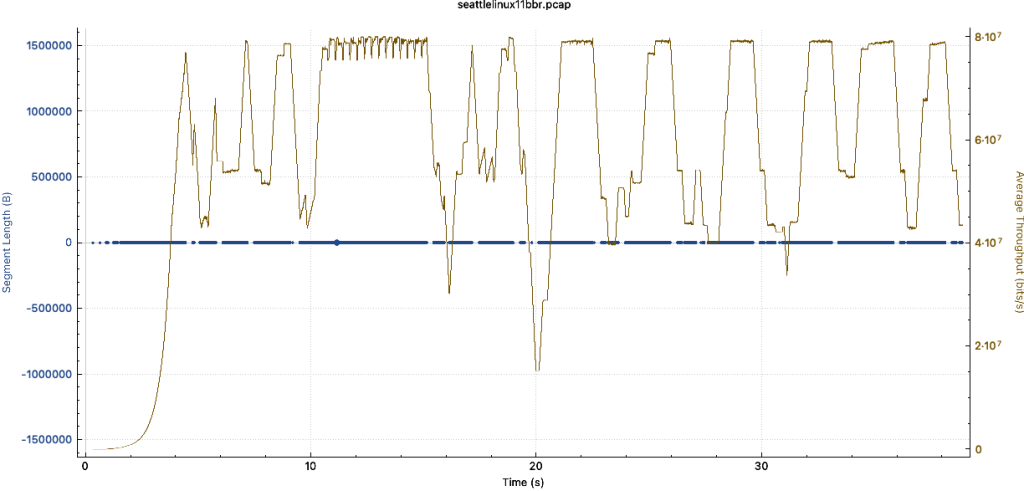
- 可以发现虽然服务端没开启BBR,但是窗口大小并没有受到非常大的影响,但A场景下的带宽非常不稳定,峰值带宽是可以达到30MBps的,与B一致,但吞吐一直处于非常不稳定的抖动中。
- 而对比3和4又能知道,在这种情况下,服务端开BBR并没有对吞吐有优化效果,因为后端到代理的后端吞吐实际上是正常的。
- 基于此情况,在客户端上对客户端进行抓包,看具体情况,A场景下表现出明显的拥塞造成吞吐衰减的情况
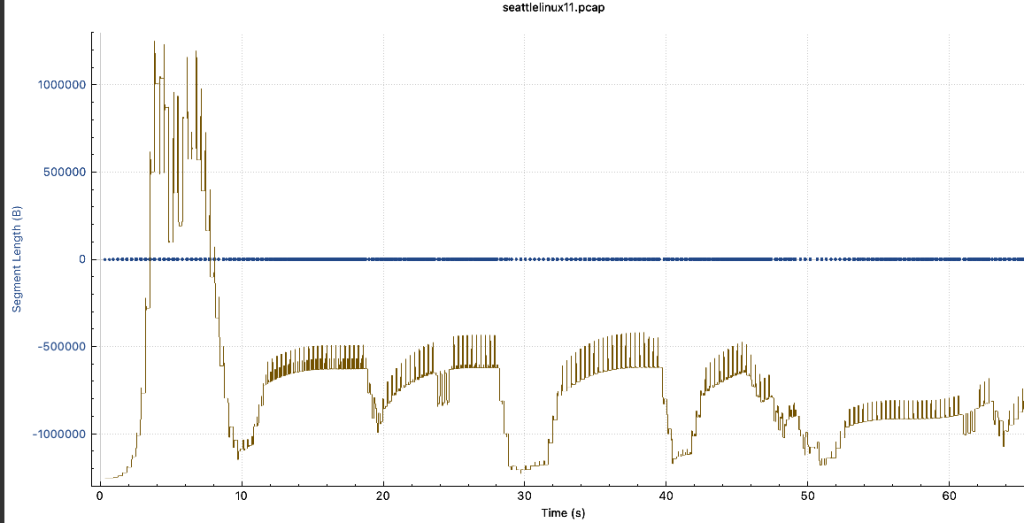
- 在nginx服务器上开启BBR后,再次抓包观察,客户端下载文件性能明显提升,且从抓包可看出窗口大小也不局限于比较小的场景,即使服务端没有开bbr,依然可以达到不错的下载效果,但是从下载场景而言,效果没有服务端开BBR直连下载的效果好(因为这次实验部署的代理和客户端之间的链路也很长),最终是看客户端到请求端的延迟与丢包的影响情况。(带宽大概在8-9MB/s上下)。
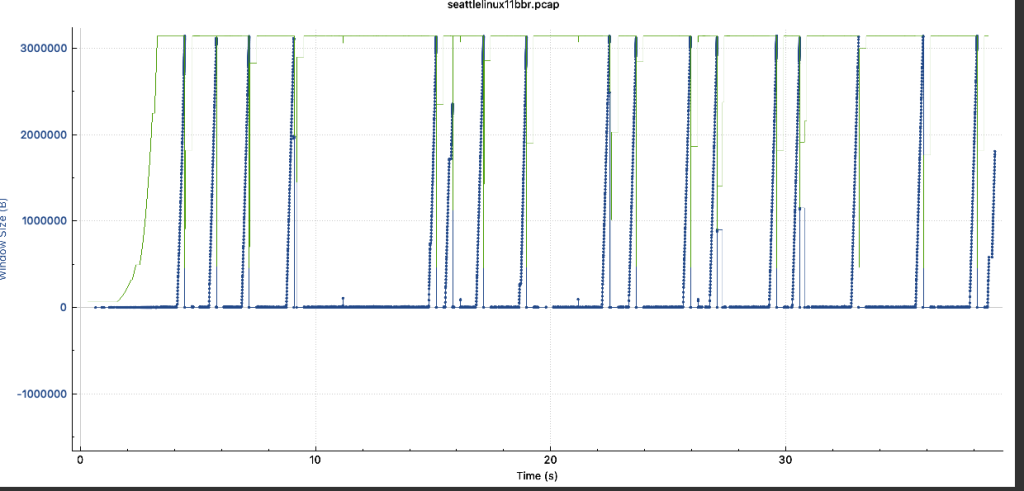
- 基于此实验与收集到的信息可得出结论:
- 在下载场景下,与客户端建立TCP连接的服务器开启BBR是必要的,实际上经过不稳定长肥管道建立tcp的两端,都建议尽量开启BBR。
- 若后端服务器与代理之间链路性能稳定,则后端服务器开不开BBR都无所谓。
- NLB的本质是三层转发,并不缩短TCP连接的延迟,故对吞吐的优化不起到作用。
- AWS的ALB目前不支持开启BBR,且其仅支持http协议端口,故对场景不具备普适性。
- 考虑到客户端并不都支持打开BBR,故最佳实践为:
- 在临近用户侧,且与后端服务端之间不存在弱网连接(比如基于自有物理核心网的纯内网环境)的地方,创建代理服务器。
- 代理服务器开启BBR。
5.3 G108na场景下读写性能差异问题定位
- 在实际场景中我们发现,从海外研发云环境对国内Gitlab进行读写的时候,写的吞吐比读要高一倍。
- 海外研发云机器开启了BBR
- 基于此情况,G108na对应SRE进行了抓包。根据抓包数据我们进行如下分析
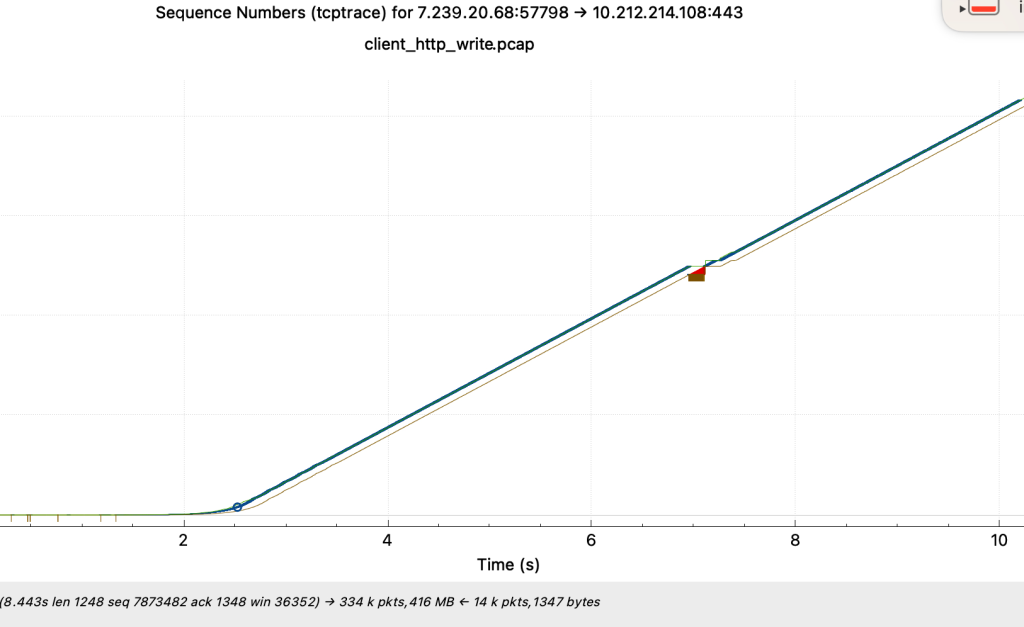
- 如下为客户端写的抓包情况
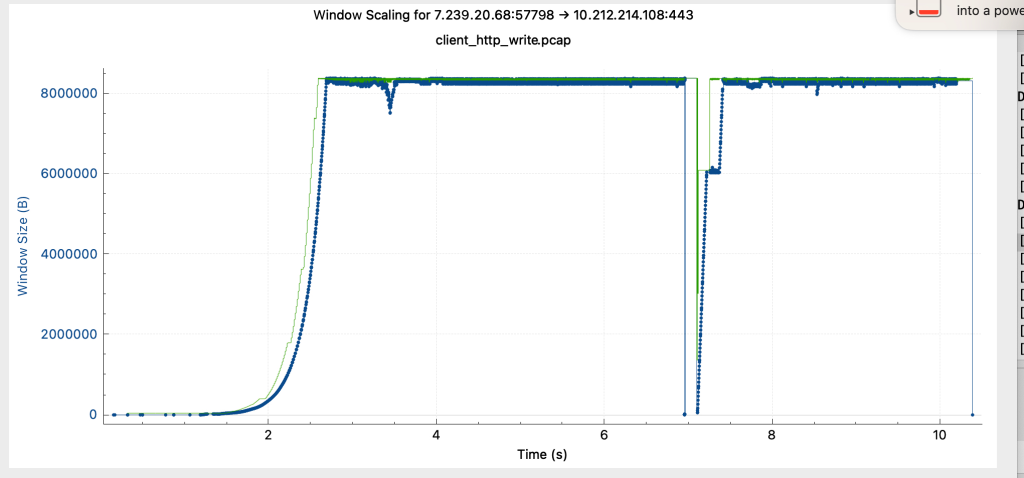
- 绿色为接收窗口大小,蓝色为发送数据,可观察到接收窗口被充分利用了,发包也比较丝滑
- 对比客户端读数据的抓包情况
- 可观察到,接收窗口虽然较大,但是发送方窗口一直上不去,发包经常出现暂缓等待发包的场景。
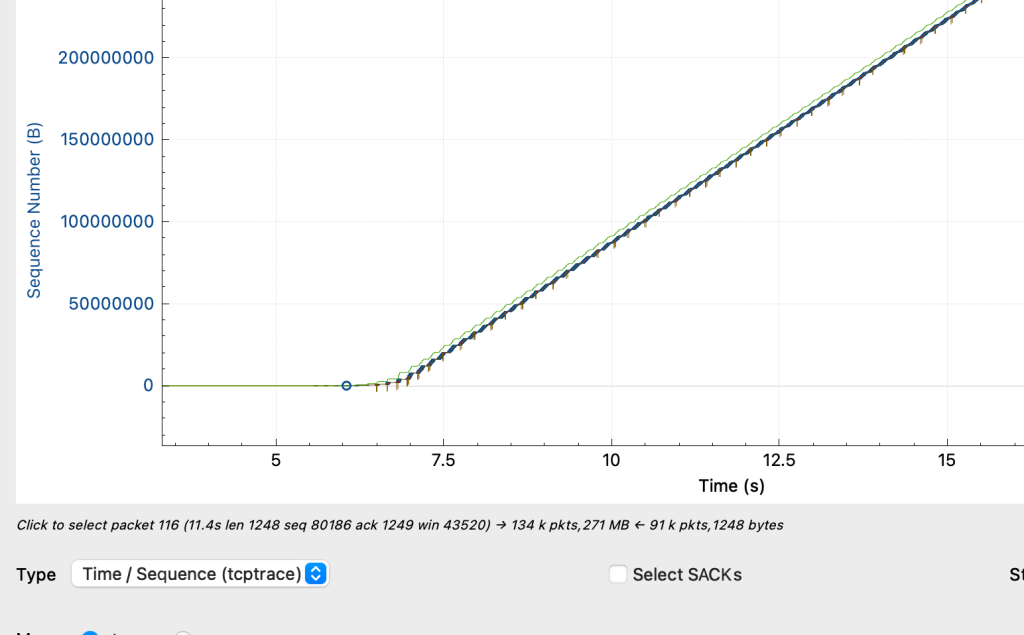
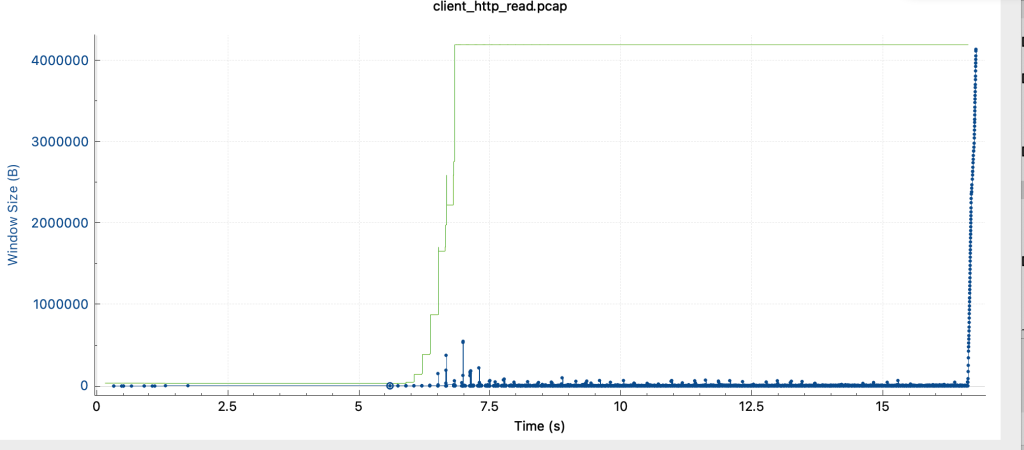
- 故可知,读性能因发送窗口大小被限制,而无法顺滑发包,导致性能上不去。
- 实际由网络以及保障组大佬定位发现:
- gitlab的出口elb容器的bbr没有被开启
- 宿主开启bbr后,新创建或者重建的容器才会开启bbr
六. 实验优化与反思
- 其实为了证明的确是因为TCP拥塞控制导致的这一现象,应该一开始做一次UDP的压测,而UDP压测的结果,其带宽应该是不会衰减的。
- 发送端压600Mbits/s的UDP,从发送端本地出口(500Mbits/s),经过VPN隧道,接收端在高唐物理机(150ms),收到了457Mbits/s的UDP流量