grep、sed、awk
1、通配符类型
基本5种类型: * 、{} 、[] 、[^]、?、
*通配符 匹配所有内容
**举例: find /etc -type f -name “*.con**
找出/etc下面所有以.conf结尾的文件 -f 文件 -d 目录)
find /etc/ -type f -name ·*abc* ·
找出/etc下所有包含abc的文件
{}通配符 生成序列
echo {1..10}
1 2 3 4 5 6 7 8 9 10 直接输出10
echo {a..t}
a b c d e f g h i j k l m n o p q r s t
echo 123{a..p}
123a 123b 123c 123d 123e 123f 123g 123h 123i 123j 123k 123l 123m 123n 123o 123p
echo 123{a,g,t}
123a 123g 123t
一般用于备份文件
cp /etc/hosts {,.bak} (逗号为分隔,输出的同时再备份bak)
ls -l /etc |grep hosts
hosts hosts.bak
[]通配符 匹配特定字符
[a-z] 匹配小写字母 1个中括号等于1个字符
[^]取反排除
? 匹配任意字符
例如匹配7个字符的文件 ls -l /root/??????? -rwxrwxrwx. 1 root root 530 Aug 22 06:20 /root/test.sh
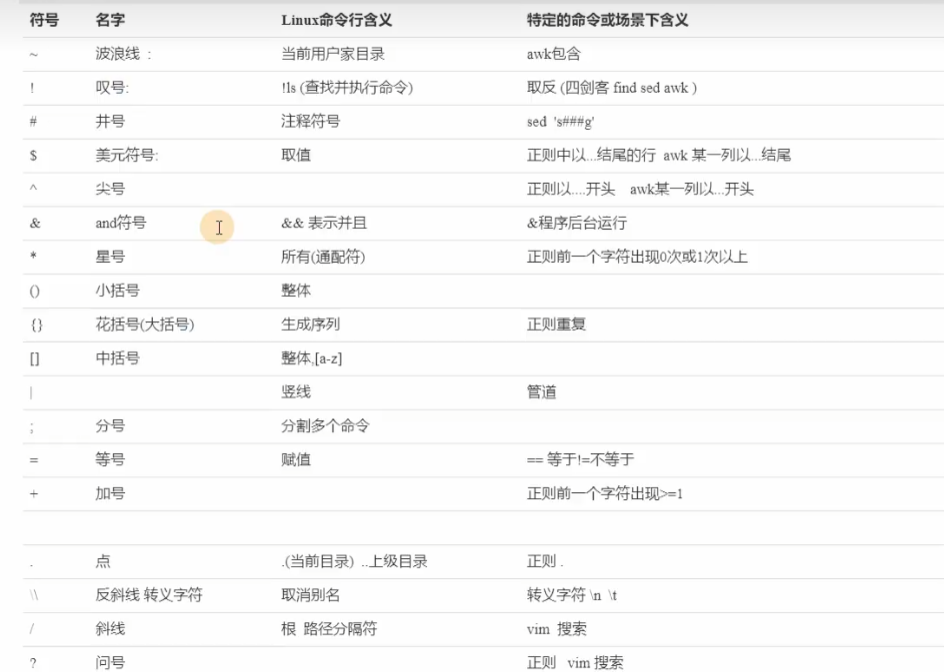
2、特殊符号
| 单引号: 里面的内容会被原封不动的输出 |
|---|
| 双引号:与双引号类似,双引号里的特殊符号会被解析运行 |
| 不加引号:与双引号类似,支持通配符 |
| 反引号:优先执行反引号里的命令 |
| \ 去掉特殊符号 |
| \n 换行符 |
| \t 制表符 |
3、正则表达式
基础正则
^ $ ^$ . * .* [] [^]
1、^和$ 匹配行首或者行尾
^5 以数字5开头的字符匹配 5$ 以数字5结尾的 (无法识别空格字符)
2、^$匹配空行
空行表示一个字符也没有,如果有空格则不算,空格也算字符 排除空行和带有#的 grep -v '^$ 目录 |grep -v '#
3、 . 表示任意字符
greo '^.' 目录 以任意字符开头的行(会自动筛除空行)
过滤出以小数点结尾的文字 grep ‘\.$’ 文件 \转义字符,去掉.的特殊含义
扩展正则
| + {} () ?
4、* 表示前一个字符出现0次或0次以上
grep ‘9* /etc/test.txt 99999 正则表达式表示连续出现或所有的时候,会出心尽可能多的匹配
5、.* 表示所有或者并且
grep '^.*1' 匹配出所有开头有1的内容
grep '^n.*\.$' /目录 匹配文件中以n开头并且以.结尾的行 ^n 匹配开头的n .* 表示中间匹配任意字符 \去掉.的特殊含义 $匹配行尾
6、[] 匹配中括号里的内容
grep '[abc]' test.txt 匹配test文件里所有a、b、c的字符
或者是 grep '[0-9]' 匹配0-9 或者 [a-z][A-Z] 或者 [a-zA-Z] 范围区间 不需要加空格(空格也是字符)
7、 [^] 反选
[^abc] 匹配不是a 不是b 不是c的内容
扩展正则
1、+ 匹配连续出现的
例1: 匹配多个0 egrep ‘0+’ 例2: 匹配连续出现的数字 egrep '[0-9]+' 例3: 匹配连续出现的字母 egrep '[a-Z]+' (不加+号,匹配的是单个字母,加了以后会匹配单词) 如果在egrep后加上 -o 就会把得到的结果筛选出来
2、| 或者
egrep 'abc|def' t.txt 筛选出有abc和def的内容(可以是单词) (注意需要加单引号)
3、{} 范围里前一个字符,连续出现,最多出现了n次
egrep '1{1,3}' t.txt 匹配连续出现1 1到3次的(但会匹配多次,如果1出现5次,可能会被拆分会出现3次,2次)
egrep '' 匹配连续出现3次的数字 例如:egrep '0{3}' 会匹配出现3次以上0的内容,包括3次
4、()里的内容视为一个整体
egrep 'tes(t|x)y' 能找到 testy和 tesxy这两个字符
5、 ?表示前一个字符出现0或者1次
egrep 'go?d' test.txt 能得到 god或者gd,但找不到good,因为?前的o出现了2次
grep其他命令
-n 行号 -v 排除 -i 不区分大小写 -o显示过程 -w 精确匹配 -R 递归查找 -l 只显示文件名 -A/-B/-C 过滤的时候显示内容及上一行或下一行或者上下行(后续需跟数字配合,如-A1(显示下行)-B1(显示上行)
2、Sed 增删改查、取行替换
执行过程:
sed命令处理过程是一行一行处理的,读取文件一行后,存放在内存中,在通过sed命令判断是否满足,如果满足就执行对应命令,不满足就继续读取下一行,默认读取到最后一行
命令格式:
-n 取消默认显示所有行,一般配合p使用 配合d,则是删除 c、a、i是添加 s是替换 -r 支持扩展正则 sed -nr '/te|st/p' t.txt 选出有te或者st的内容 -i是修改文件内容
1、显示指定行
sed -n '3p' test.txt 显示文件的第三行
sed -n '2,4p' test.txt 显示文件的2到4行
sed -n '//p' test.txt 附带正则表达式 //之间可以写正则表达式,如 sed -n'/[0-9]/' t.tx
sed -n '/102/,/104/p' txt.txt 显示包含102到104行
sed -n '/10:00:00/,/11:00:00/p' access.log |less 按页显示10:00:00到11:00:00的内容 less按页
2、删除指定行 (不是真的删除,只是筛选)
sed '3d' test.txt 删除第三行
sed '3,5d' test.txt 删除3到5行
sed '/test/d' test.txt 模糊删除带有test的行 或者 sed -r '/te|st/d' t.txt 带有te和st的行
sed -r '/^$|#/' test.txt 删除空行或者注释的行
3、增加(不是真的增加)
sed '2i 123'test.txt 在第二行上面插入一行
sed '2a 123'test.txt 在第二行下面追加一行
sed '2c 123'test.txt 把第二行整行替换掉
4、真正的修改
sed -i 加上面的增删修改 sed -i.bak 备份后再修改,修改的是源文件
5、替换或者删除
sed 's/目标/替换成什么/g' 文件 g是全局替换 /可以换成#或者@
sed 's/目标/替换成什么/g' 文件 替换的目标为空的时候,则是替换为空(视为删除)
sed 's/[0-9]//g' 文件 把0到9的数字删掉,不是整行
sed 's/[0-9]{3}/go/g' 文件 将每一行开头的3位数字替换为go
6、反向引用
将前面里的内容保护起来,执行后面的命令去引用
echo {1..10} |sed -r 's/[0-9]+/<\1>/g' 输出1~10,将1到10里([0-9]+)保护起来,给他们加上<>
sed -r 's/^([0-Z-]+)(:.*:)(.*$)/\3/' txt 把数字开头的文件切割出来为区域1 :后到:中间的为区域2 任意结尾的为区域3 \3则是输出区域3 如果倒着输出就是sed -r 's/^([0-Z-]+)(:.*:)(.*$)/\3\2\1/' txt
3、awk
特殊符号
| NR:行号 NF:最后一列 column -t 排序后输出 ~代表某一列中包含什么 $0 代表整行{print $0} |
|---|
1、awk取行
NR命令=行号 awk 'NR==3' test.xtt 获取第三行 类似于 sed -n '3p' test.txt 注意一个=是赋值,2个=才是等于
awk ‘NR>=2 && NR<=5’ test,txt 获取行号大于2,小于5的行
awk '/test/' test.txt 获取带有test的行 asw'/test|go/' test.txt 获取带有test或go的行
awk '/test/,/go/' test.txt 显示包含test到包含go的行
2、awk取列
cat /root/test.txt | awk '{print $3}' 取第三列,以空格为间隔做列
cat /root/test.txt | awk '{print $NF}' 取最后一列, NF是获取最后一列
cat /root/test.txt | awk '{print $NF,$1,$3}' 取最后一列,第一列,第5列 NF是获取最后一列
进阶
awk -F : '{print $1}' test.txt 将:作为分隔符,输出第一列 在后面加上 column -t 排序后输出
awk -F '[ /]+' '{print $2}' test.txt 将连续的空格和/作为分隔符,输出第二列
3、awk 过滤
awk '/test/' test.txt 过滤出有test的内容
awk -F: '$3 ~ /^1/' test.txt 过滤出第三列包含数字1的行 ~代表某一列中包含什么,可以支持正则
awk -F: '$4 ~ /[0a]$/' test.txt 过滤出第3列以数字0或者a结尾的行
awk -F: '$4 ~ /[0a]$/{print $1,$4}' test.txt 过滤出第3列以数字0或者a结尾的行,只显示第一列和第四列
4、awk删除

awk ‘!/^$|^[ \t]+$/’ test.txt 删除空行或者以空格开头或者tab键( \t)的行 !删除
5、awk begin{} 读取文件前执行,输出
读取第一列第三列,然后在前面追加name和uid,并排序
6、计数
awk '/^$/{i++}END{print i}' /etc/passwd 统计passwd有多少行,用END{}输出 或者wc -l更便捷
4、重定向

1、tc命令 替换
tr 'a-z' 'A-Z' <test.txt 将小写的a-z替换成大写的A-Z并输出,并不是真的修改
2、EOD 向文件中写入多行内容
cat >test.txt<<EOF TEST(内容) EOF结束 或者是 cat <<EOF >test.txt 内容 EOF结束 >代表先清空文件再追加
3、tee 输出的同事可以追加或者覆盖
echo {1..10} |tee test.txt 输出1到10,然后再覆盖到test.txt文件里
echo {1..10} |tee -a test.txt 输出1到10,然后再追加到test.txt文件里
5、符号含义