日常在网络运维过程中,如果出现网络问题,更多的是网络设备、网络协议、网络基础设施(如:DNS、DHCP、AD域、行为管理、防火墙等)一般情况下,如果在没有网络变更,网络出现问题,更多的是网络协议的问题,但是在服务器上,尤其是linux设备,遇到网络问题的时候,很多从事网络方面的人,都不知道如何处理,在有些紧要的时候,我自己也没办法很灵活的回想起很多的命令,所有写这篇文章记录一下。
1、网络拥堵
网络拥堵(Network Congestion)是指网络中的数据流量超过了可用带宽,导致网络性能下降,包括数据包丢失、延迟增加和吞吐量降低等问题
产生原因
- 高流量应用:例如视频流、文件传输、在线游戏等高带宽需求的应用。
- 恶意攻击:如DDoS攻击,试图通过大量请求使网络过载。
- 网络配置不当:路由器、交换机或其他网络设备的配置不当。
- 硬件限制:网络设备或服务器网卡的性能限制。
- 网络拓扑:不合理的网络架构,导致瓶颈。
判断依据
高延迟和丢包:使用`ping`命令测试延迟和丢包率。
ping wooring.cn |
网络带宽使用情况:
- 使用ifstat命令查看网络接口的实时带宽使用情况。
ifstat eth0 1 - 使用iftop命令实时监控网络流量。
iftop-ieth0
网络连接和接口统计:使用netstat命令查看网络连接和接口统计信息。
netstat -inetstat -s |
网络路径和延迟:使用traceroute命令查看数据包的传输路径和延迟。
traceroute wooring.cn |
通过网络抓包:通过使用tcpdump命令进行抓包,使用wireshark中观察tcp中是否存在大量的重复ACK包和重传数据包,过滤器为:tcp.analysis.duplicate_ack 或 tcp.analysis.retransmission
解决方案
流量控制和带宽管理:使用tc命令管理流量
sudo tc qdisc add dev eth0 root tbf rate 1mbit burst 32kbit latency 400ms# 对网络接口eth0应用一个流量控制规则,限制其平均传输速率为1Mbps,允许32千位的突发流量,并设置最大延迟为400毫秒 |
优化网络配置:调整TCP/IP参数,修改/etc/sysctl.conf文件中的参数,如增大TCP缓冲区
net.ipv4.tcp_rmem = 4096 87380 6291456## TCP接收缓冲区的大小,最小接收缓冲区大小为4096字节,默认接收缓冲区大小87380字节,最大接收缓冲区大小6291456字节net.ipv4.tcp_wmem = 4096 16384 4194304# TCP发送缓冲区的大小,最小发送缓冲区大小、默认发送缓冲区大小、最大发送缓冲区大小,单位字节net.core.rmem_max = 16777216# 任何socket接收缓冲区的最大大小(字节),设置了TCP/IP协议栈允许的最大接收缓冲区大小。net.core.wmem_max = 16777216#任何socket发送缓冲区的最大大小(字节)。这个值设置了TCP/IP协议栈允许的最大发送缓冲区大小。sudo sysctl -p #应用更改 |
升级硬件:
- 升级网络设备,例如替换老旧的路由器、交换机和防火墙,使用千兆以太网或更高带宽的网络设备;
- 增加服务器网卡数量和带宽,使用多网卡绑定(NIC bonding)、多链路聚合,以增加带宽和冗余
负载均衡:使用负载均衡器,配置负载均衡器(如Nginx、HAProxy)分发流量
安全措施:防御DDoS攻击、限制不必要的网络访问,增加防火墙规则限制外部网络访问
模拟场景
使用tc工具来模拟网络拥堵的场景,命令如下
sudo tc qdisc add dev eth0 root handle 1:0 netem delay 1000ms rate 1mbit# 引入 100 毫秒的延迟、限制带宽为 1 Mbps |
通过wireshark工具来进行抓包(使用ping命令)
使用tcp.analysis.duplicate_ack来过滤重复的ack包
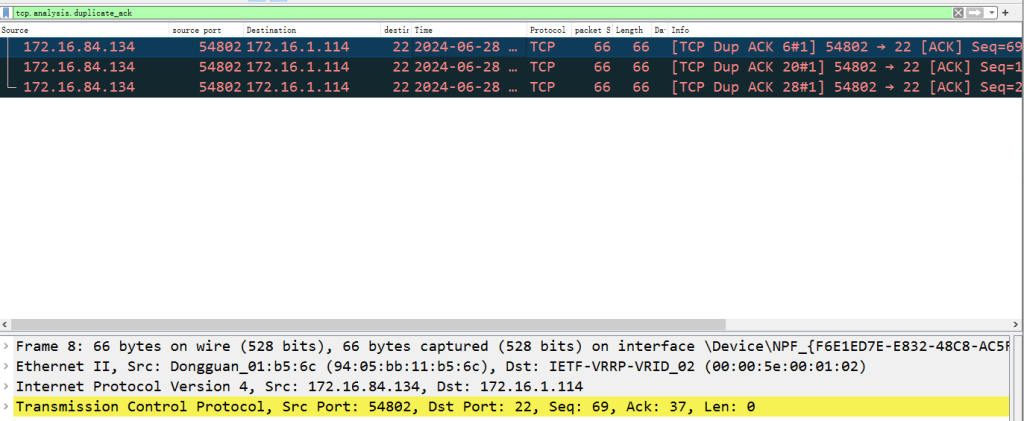
使用tcp.analysis.retransmission过滤重传包
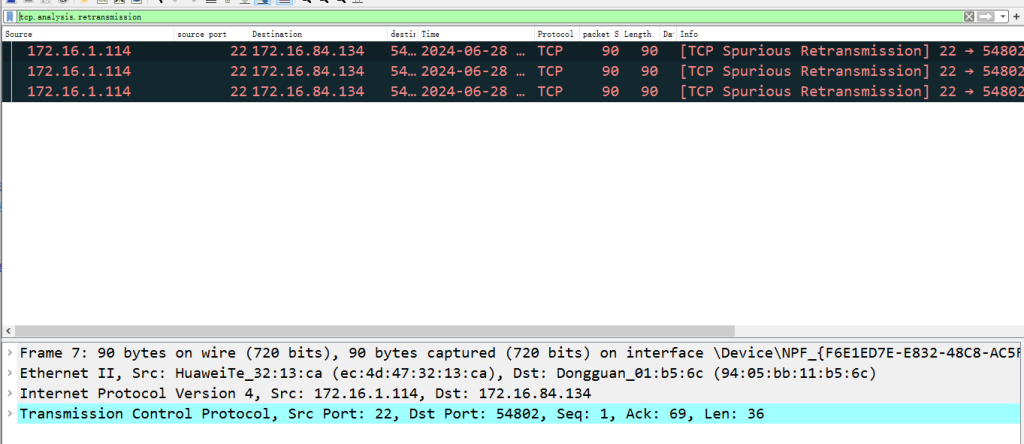
模拟完成后记得在服务器上使用sudo tc qdisc del dev eth0 root来清除这个配置
2、网络丢包
网络丢包(Packet Loss)是指在数据传输过程中,网络设备未能成功传递一个或多个数据包到目标位置。丢包现象会导致网络性能下降,影响应用程序的响应速度和稳定性。
产生原因
网络拥塞:网络中的数据流量过多,超过了网络设备的处理能力,导致数据包被丢弃。
硬件故障:路由器、交换机、网卡等网络设备存在故障或损坏。
网络干扰:无线网络受到电磁干扰或信号强度不足,导致数据包丢失。
网络配置不当:网络设备配置错误,如MTU(最大传输单元)设置不当,导致数据包被截断。
网络设备超负荷:网络设备负载过高,无法处理所有传入和传出的数据包。
链路质量差:物理链路的质量问题,如老旧或损坏的电缆。
判断依据
使用 ping命令:ping 命令可以测试到目标主机的连通性和丢包率。
ping -c 10 ns.mosapi.cn |
使用 traceroute命令:traceroute 命令可以显示数据包到达目标主机的路径,并帮助检测在每一跳的响应时间和丢包情况。
traceroute ns.mosapi.cn |
使用 netstat命令:netstat 命令可以显示网络接口的统计信息,包括丢包统计。检查输出中的 RX-ERR 和 TX-ERR 列,表示接收和发送数据包时的错误数。
netstat -i |
通过网络抓包:通过使用tcpdump命令进行抓包,使用wireshark中观察tcp中是否存在丢失的数据包,过滤器为: tcp.analysis.lost_segment
解决方案
优化网络配置
- 调整MTU:确保所有网络设备的MTU((Maximum Transmission Unit)指的是网络接口上能够传输的最大数据包(报文)大小,单位字节)值一致,避免数据包截断。
ifconfig eth0 mtu 1500# 设置 MTU 值为 1500 - 配置流量控制:使用 tc 工具管理流量,避免网络拥塞。
sudo tc qdisc add dev eth0 root tbf rate 1mbit burst 32kbit latency 400ms#rate 1mbit: 限制 eth0 接口的平均传输速率为 1Mbps。这个参数确保接口不会超过此速率。#burst 32kbit: 允许一个 32 千位的突发数据量。突发量表示在短时间内可以传输超过 rate 限制的数据量,适用于处理突然的流量高峰。#latency 400ms: 设置最大允许的队列延迟为 400 毫秒。这个参数限制数据包在队列中等待处理的时间,防止队列过长导致的延迟过大。
升级和维护硬件
- 检查并更换有故障的硬件:定期检查网络设备,如路由器、交换机和网卡,确保它们正常工作。
- 升级网络设备:使用性能更高的网络设备,如千兆交换机和路由器,提高网络处理能力。
增加带宽和分布负载
- 增加网络带宽:根据需要升级网络带宽,减少网络拥塞。
- 使用负载均衡:将流量分布到多台服务器上,避免单点瓶颈。
改善无线网络
- 减少干扰:确保无线设备远离电磁干扰源,如微波炉和无线电话。
- 优化信号覆盖:调整无线设备的位置或增加中继器,确保信号覆盖范围充分。
使用网络监控和管理工具
- 实时监控网络性能:使用网络监控工具,如 Nagios、Zabbix、Prometheus 等,实时监测网络性能,及时发现和解决问题。
- 定期审计网络配置:定期检查和优化网络配置,确保网络设备和配置符合最佳实践。
模拟场景
使用tc工具来模拟网络丢包的场景,命令如下
sudo tc qdisc add dev eth0 root handle 1:0 netem loss 10%# 增加丢包率为10% |
通过wireshark工具来进行抓包(使用ping命令)
使用tcp.analysis.lost_segment来过滤未捕获到的tcp包
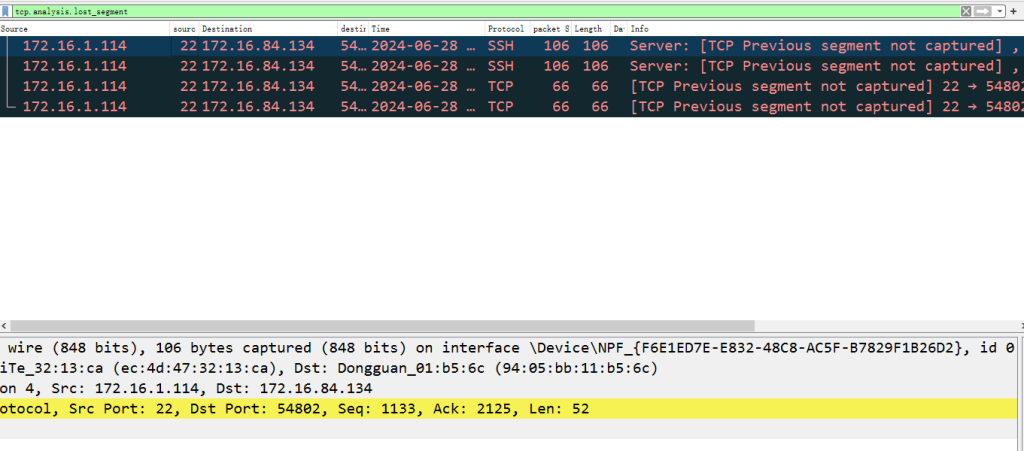
使用tcp.analysis.retransmission过滤重传包
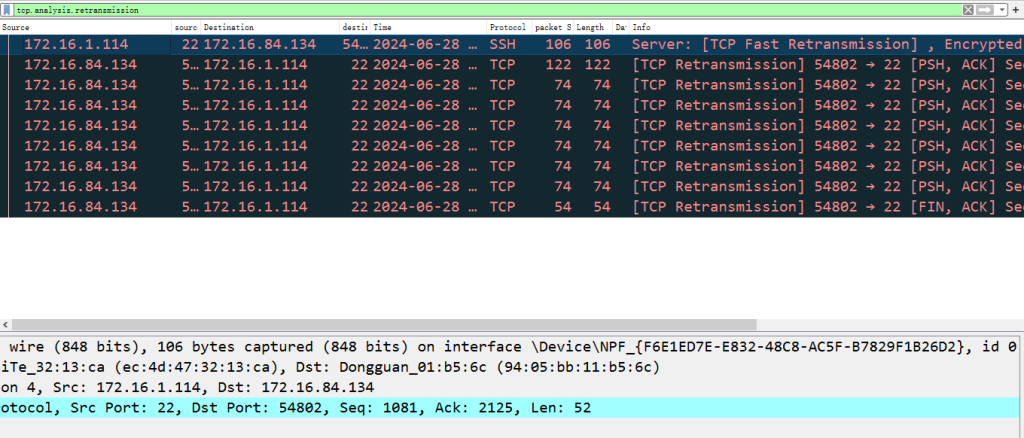
3、网络闪断
网络闪断是指网络连接短暂中断或不稳定,导致数据传输中断或延迟的现象。
产生原因
网络设备故障:路由器、交换机或网卡等设备的硬件故障或配置问题
网络负载过高:突然的高流量或带宽需求超过了网络设备的处理能力;高并发连接导致的设备过载。
干扰:无线网络受到电磁干扰,如微波炉、蓝牙设备等;邻近无线网络的干扰(Wi-Fi 信道冲突)。
判断依据
使用 ping命令:ping 命令可以检测到目标主机的连通性和丢包情况。如果出现持续的响应时间不稳定或高丢包率,可能存在网络闪断问题。
使用 traceroute命令:traceroute 命令可以追踪数据包到达目标主机的路径,并检测每一跳的响应时间。如果某一跳的响应时间不稳定,可能是该节点或其连接的问题。
解决方案
检查和维护网络设备
- 定期检查:定期检查路由器、交换机和网卡等网络设备的状态,确保它们正常工作。
- 固件更新:确保网络设备的固件为最新版本,修复已知的漏洞和问题。
- 设备更换:如果设备老化或频繁出现问题,考虑更换性能更好的设备。
实施网络冗余
- 多路径传输:配置多路径传输(如 BGP 多路径)以提高网络可靠性。
- 冗余设备:配置冗余路由器和交换机,确保单个设备故障不会导致网络闪断。
优化网络配置
- 调整网络配置:优化路由器和交换机的配置,确保合理的负载均衡和带宽管理。
- 无线网络优化:调整 Wi-Fi 信道,避免与邻近网络冲突,减少干扰。
4、大量CLOSEWAIT 和 TIMEWAIT
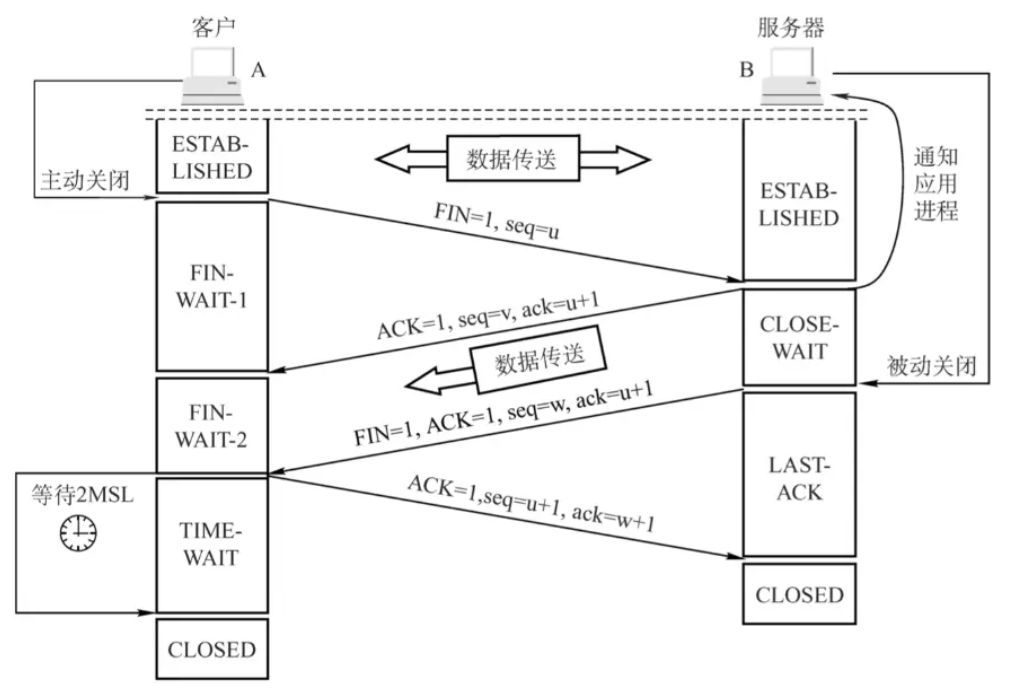
4.1、CLOSE_WAIT
它表示连接的一端已经接收到另一端发送的 FIN(finish)报文,表示对方已经关闭了连接。这时,连接处于 CLOSE_WAIT 状态,意味着本端还没有完全关闭连接,需要应用程序执行关闭操作以释放连接资源。
产生原因
应用程序未能正确关闭连接:程序接收到了 FIN 报文,但未能及时调用 close(),可能是因为程序设计问题或者处理逻辑不当。
资源泄露:程序可能忘记了关闭连接,导致连接一直处于 CLOSE_WAIT 状态。
判断依据
使用 netstat检查 CLOSE_WAIT状态,这个命令会显示所有处于 CLOSE_WAIT 状态的连接。
netstat -an | grep CLOSE_WAIT |
使用 ss工具检查详细信息,这个命令也会显示所有处于 CLOSE_WAIT 状态的连接,ss 工具通常比 netstat 更加现代化和高效。
ss -tan state CLOSE-WAIT |
找出对应的进程,这个命令会列出所有与 CLOSE_WAIT 状态相关的进程和文件描述符。
lsof -i | grep CLOSE_WAIT |
解决方案
分析和修改应用程序代码
- 检查连接的生命周期:确保所有打开的连接最终都会调用 close() 关闭。
- 正确处理异常:确保程序在异常情况下也能正确关闭连接,避免资源泄露。
- 超时设置:设置合理的连接超时,防止长时间的CLOSE_WAIT。
预防 CLOSE_WAIT
- 良好的编程习惯:确保所有网络连接在完成后都能正确关闭。
- 定期监控:使用监控工具定期检查连接状态,及时发现和处理异常状态。
- 日志记录:记录连接的建立和关闭日志,帮助分析问题。
4.2、TIME_WAIT
表示连接的一端(通常是主动关闭连接的一端)已经发送并确认了 FIN(finish)报文,且已经接收到对方的 FIN 报文。此状态主要用于确保网络上的延迟数据包不会影响后续的连接。
产生原因
短连接频繁建立和关闭
- 短连接(Short-lived Connections):应用程序每次请求都建立一个新的 TCP 连接,然后立即关闭。这在高频次请求的情况下会导致大量的 TIME_WAIT 状态。
- HTTP/1.0 协议:默认使用短连接,每次请求都会新建一个连接并在响应后关闭。
高并发的网络服务
- 高并发网络服务:如高流量的 Web 服务器、API 服务等。这些服务在处理大量客户端请求时,会频繁打开和关闭连接,导致大量 TIME_WAIT 状态。
短时间内的大量请求
- 批量请求:在短时间内进行大量的批量请求测试或数据传输操作,这些操作频繁建立和关闭连接,容易产生大量 TIME_WAIT 状态。
不合理的连接管理策略
- 缺乏连接重用:没有实现连接池或保持长连接的机制,使得每次请求都建立一个新的连接。
- 不当的负载均衡:负载均衡策略不当,导致单个服务器处理过多请求,频繁进入 TIME_WAIT 状态。
判断依据
使用 netstat检查 TIME_WAIT状态,这个命令会显示所有处于 TIME_WAIT 状态的连接。
netstat -an | grep TIME_WAIT |
使用 ss工具检查详细信息,这个命令也会显示所有处于 TIME_WAIT 状态的连接,ss 工具通常比 netstat 更加现代化和高效。
ss -tan state TIME-WAIT |
解决方案
调整系统参数,调整内核参数以减少 TIME_WAIT 状态的持续时间
- 减少 TIME_WAIT状态持续时间
sudo sysctl -wnet.ipv4.tcp_fin_timeout=30 # tcp_fin_timeout 参数定义了 TIME_WAIT 状态的持续时间,单位为秒。默认值通常是 60 秒,可以根据需要调整- 允许复用 TIME_WAIT状态的连接:
sudo sysctl -wnet.ipv4.tcp_tw_reuse=1sudo sysctl -wnet.ipv4.tcp_tw_recycle=1 # tcp_tw_reuse 和 tcp_tw_recycle 参数允许在 TIME_WAIT 状态下复用 TCP 连接。需要注意的是,tcp_tw_recycle 在 NAT 环境中可能会引起问题,因此在生产环境中要谨慎使用。
使用负载均衡,通过负载均衡分配流量,减少单个服务器上的连接数,从而减少 TIME_WAIT 状态的连接数
upstream backend {
server wooring.cn;
server wooring.com;
}
server {
listen 80;
location / {
proxy_pass http://wooring.cn;
}
}5、常用的linux网络调优参数
这些参数通常配置在 /etc/sysctl.conf 文件中,然后通过运行 sysctl -p 命令使其生效
| net.ipv4.tcp_wmem | TCP发送缓存(单位:字节) net.ipv4.tcp_wmem = 4096 16384 4194304 4096: 每个 TCP 连接的最小发送缓存大小。16384: 每个 TCP 连接的默认发送缓存大小。4194304: 每个 TCP 连接的最大发送缓存大小。 |
| net.ipv4.tcp_rmem | TCP接收缓存(单位:字节) net.ipv4.tcp_rmem = 4096 87380 6291456 4096: 每个 TCP 连接的最小接收缓存大小。87380: 每个 TCP 连接的默认接收缓存大小。6291456: 每个 TCP 连接的最大接收缓存大小。 |
| net.core.rmem_max | 最大接收缓冲区net.core.rmem_max = 16777216 套接字最大接收缓冲区大小 |
| net.core.wmem_max | 最大发送缓冲区net.core.wmem_max = 16777216 套接字最大发送缓冲区大小 |
| net.ipv4.tcp_syn_retries | TCP SYN 重试次数(建立连接时)net.ipv4.tcp_syn_retries = 2 |
| net.ipv4.tcp_synack_retries | TCP SYN ACK 重试次数 net.ipv4.tcp_synack_retries = 2 |
| net.ipv4.tcp_fin_timeout | TCP FIN 等待时间 net.ipv4.tcp_fin_timeout = 30 设置处于 FIN-WAIT-2 状态的套接字关闭前的等待时间。 |
| net.ipv4.tcp_tw_recycle | 启用 TIME-WAIT 套接字的快速回收net.ipv4.tcp_tw_recycle = 1 |
| net.ipv4.tcp_tw_reuse | 允许在 TIME-WAIT 状态下重用套接字net.ipv4.tcp_tw_reuse = 1 |
| net.core.somaxconn | 增加内核维护的可处理请求队列长度net.core.somaxconn = 4096 设置系统中每个端口最大的监听队列的长度。 |
| net.ipv4.tcp_mem | TCP 内存参数net.ipv4.tcp_mem = 94500000 915000000 927000000 94500000: TCP 内存使用达到此值时启动收缩。915000000: 在压力下进入 TCP 内存收缩状态的内存量。927000000: 内存耗尽时最大允许的内存量。 |
| fs.file-max | 增加最大文件句柄数fs.file-max = 1000000 设置系统允许打开的最大文件数(包括网络连接) |