linux系统中:
文件系统三个方面:
- Disk相关参数调优(DISK就是磁盘相关配置参数)
- 文件系统本身参数调优
- 文件系统挂载(mount)参数调优
DISK参数配置
- yum install sdparm(安装sdparm工具)
- sdparm -s WCE=1,RCD=0 -S /dev/sdb(这个命令的意思是开启写缓存,关闭读缓存,)
注意点:将导致/dev/sdb的写缓存启动且读缓存禁用,写入的数据将首先缓存在磁盘的内存中,然后异步写入磁盘,不会立即确认读取操作,故写入性能提高了,但是会有风险。
风险:数据丢失风险:启用写缓存意味着写入的数据会先被缓存在磁盘的内存中,而不是立即写入磁盘,如果在数据被写入磁盘前系统崩溃或者断电,数据可能会丢失。
数据一致性风险:禁用读缓存可能导致读取到过期或者无效的数据。因为读操作不会直接从磁盘中获取数据,而是从缓存中读,如果写操作还没有完成或者其他未同步的操作,读取的数据可能不是最新的或不正确的。
场景:假如在使用某个数据库应用程序,并且将数据存储在/dev/sdb这个磁盘设备上,这个时候启用写缓存并禁用读缓存以提高性能。如果在某一时间,执行了一个重要写操作,将一些关键数据写入数据库。由于启用了写缓存,写入的数据首先被存在磁盘中,而不是立即写入磁盘,然后,在数据还没有正式写入磁盘前,系统突然宕机或者断电,这时就会丢数据了,这是一个风险例子。
- Linux I/O scheduler算法(linux系统I/P调度算法)
在重负载情况下,deadline调度方式对squid I/O负载具有更好的性能表现。其他三种还有noop(fifo),as,cfq,noop多用于SAN/RAID存储系统,as多用于大文件顺序读写。sfq适用于桌面应用。
echo deadline > /sys/block/sdb/queue/scheduler
deadline调度方式:I/O调度策略,用于处理块设备的读写请求顺序
- I/O请求延迟:以最短的延迟响应I/O请求。更加关注于I/O操作的响应速度。
- I/O请求排序:根据I/O请求的截止时间进行排序,以确保高优先级的请求尽快完成,有助于减少I/O请求等待时间,提高系统响应性能。
- 时间片分配:为每个进程分配时间片,在该时间片内进行I/O操作,有助于减少I/O资源被某个进程独占。提高系统吞吐量。
squid I/O负载:一种代理服务器和缓存服务器,加速Web请求并减轻服务器负载。通常指Squid服务器处理客户端请求和与后端服务器通信时的磁盘操作读写操作,包括缓存数据的读取和写入、日志记录、访问控制列表等。
一般需要调整缓存大小、调整squid的并发连接数,减轻服务器的I/O负载并提高响应速度。
对于redhat linux,read_expire=1/2 write_expire,对于大量频繁的小文件I/O负载,应当取这两者较小值。更适合的值。
这里做的实践:
1)
mkdir /home/test_dir
cd /home/test_dir
for i in {1..10000}; do dd if=/dev/zero of=file$i bs=1K count=1; done
(创建一个测试目录,生成10000个1kb的文件)
2)
启用参数read_expire和write_expire.两个参数针对内核中的Page Cache缓存机制,用于调节缓存数据的过期时间,
实验:
将read_expire和write_expire分别设置为1和2,意思是读取数据的缓存将在1秒后过期,写入数据的缓存在2秒过期。
echo 1 > /proc/sys/vm/vfs_cache_pressure
echo 2 > /proc/sys/vm/dirty_expire_centisecs
测试:
time find . -type f -exec cat {} \; > /dev/null(对所有文件得内容读取出来并且将其丢弃,使用time测量运行时间)
time for i in {1..10000}; do echo “test” > file$i; done(对所有文件进行写入操作,使用测量运行时间)
更改了读取数据缓存过期时间和写入数据得缓存过期时间后结果如下:
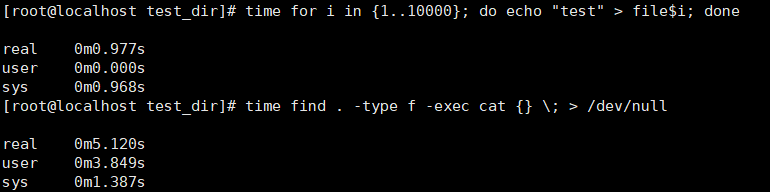
更改了读取数据缓存过期时间和写入数据得缓存过期时间前结果如下:
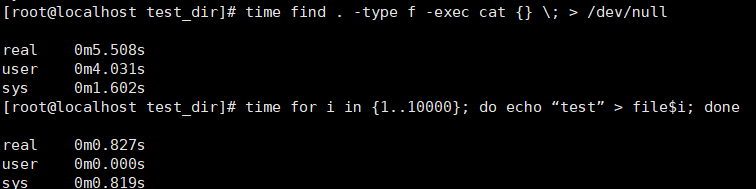
会又一些提升。
3)
readahead预读扇区数
预读,提高磁盘性能,目前对顺序读比较有效,主要利用数据的局部性特点,比如在一个系统上,设置了256块扇区性能较优。
实验测试过程:
安装fio工具,然后进行测试
sudo yum install -y fio
vim fio_test.fio
[global] #定义全局参数,应用于所有测试场景
ioengine=libaio #指定I/O引擎为libaio,异步I/O操作的linux内核I/O引擎,提高磁盘性能
direct=1 #直接使用I/O,绕过文件系统缓存,直接读取或写入磁盘,减少同步调用次数,提高性能
numjobs=1 #指定为单线程,并发数为1,只有一个I/O线程在执行操纵
runtime=60 #运行时间60秒,测试场景时间为60秒
time_based #指定测试以时间为基础运行,而非一定数量的I/O操作
[test]
rw=randread #随机读取测试,randwrite是随机写入,read顺序读取
bs=4k #指定每个I/O块的大小为4KB
size=1G #指定测试数据总大小为1GB
结果:
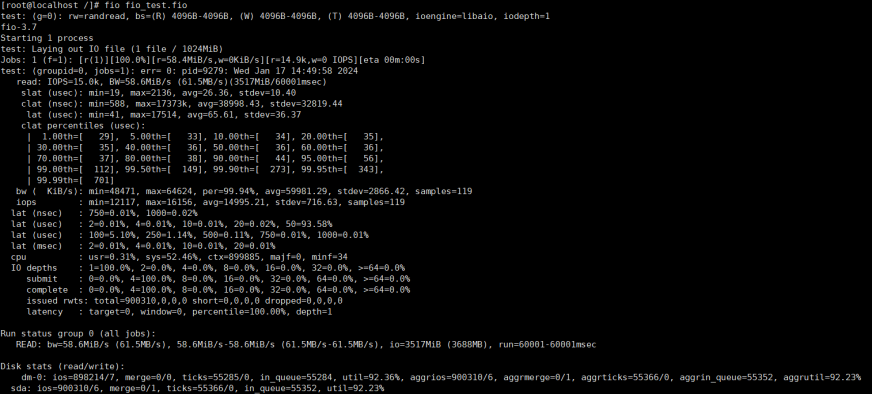
- IOPS:随机读操作的每秒输入/输出的操作数15000
- 带宽(BW):随机读操作的带宽为4MiB/s
- 平均延迟(lat):读取操作的平均延迟为61微秒(us)
- 百分位延迟(lat percentiles):99%的读取操作的延迟小于等于701微妙(us)
- I/O深度(iodepth):IO深度为1,表示每个线程在任何给定时间最多只能有一个挂起的IO请求
- CPU使用率(cpu):用户态cpu使用率为31%,系统态cpu使用率为52.46%
- IO统计信息(issued rwts):发出的读写总操作数为900310
设置通读扇区数:
blockdev –set 256 /dev/sda
每次读取操作时预知256块区域得数据,这个需要根据环境及情况去设定,小文件读取就不加了,反而降低性能,过大浪费内存资源,过小我发充分利用内存资源。
linux内存性能优化
Huge Page
TLB缓存虚拟地址到物理地址的映射关系,只有TLB cache miss的时候,才会遍历页表进行查找
TLB cache的大小有限,过多的映射关系会产生cacheline的冲刷,被冲刷的虚拟地址下次访问时又会产生TLB miss,又需要遍历页表才能获取物理地址。
linux有大页机制,就是存储TLB cache的
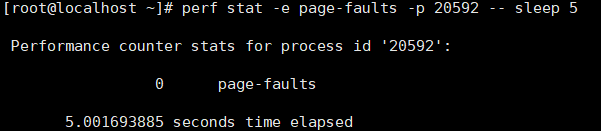
占用大内存应用程序使用大页机制分配内存,弊端:初始化耗时高,进程内存占用可能变高。用perf工具对比进程使用大页前后的PageFault次数变化;(也就是查询没有映射到物理地址的页数)
perf stat -e page-faults -p <pid> — sleep 5
目前内核提供了两种大页机制,一种是需要提前预留的静态大页形式,另一种是透明大页THP
(1)THP(Translation Lookaside Buffer):提高操作系统对大内存页的使用效率,传统是内存分为较小的页(4KB),THP允许使用更大页面存储内存映射关系。但是需要精细控制内存布局和访问模式的应用程序,在某些情况下THP可能会导致性能下降,在使用时,需要进行性能监测和监控。
- HugeTLB静态大页
设置成cmdline参数在系统启动阶段预留,指定大页size=2M,一共预留512个
hugepagesz=2M hugepagesz=512
可以在系统运行时动态预留,但该方式可能因为系统中没有足够的连续内存而预留失败。所以需要实时监控系统内存情况。
预留默认size(可以通过cmdline参数default_hugepagesz指定size)的大页:
echo 20 > /proc/sys/vm/nr_hugepages
预留预定size的大页:
echo 5 > /sys/kernel/mm/hugepages/hugepages-*/nr_hugepages
预留特定node上的大页
echo 5 > /sys/devices/system/node/node*/hugepages/hugepages-*/nr_hugepages
当预留的大页个数小于已存在的个数,则会释放多余大页(前提是未使用)
使用大页优点:
- 满足进程的分配请求
- 避免该部分内存被回收
使用大页缺点:
- 需要用户显示的指定预留的大小和数量
- 需要应用程序适配,比如:
- mmap、shmgt时指定MAP_HUGETLB;
- 挂载hugetlbfs,然后open并mmap(可以使用so,不用修改程序)
- 不可以预留太多大页内存,这样会导致free大幅减少,容易触发系统内存回收甚至OOM(内存溢出)
紧急情况内存不够如果解决?
(1)手动减少nr_hugepages,将未使用的大页释放回系统
(2)可以使用7引入的HugTLB+CMA方式
性能抖动:
(1)第一种进程内存占用可能远大所需的情况下,可能会造成free内存更少,更容易触发内存回收:系统内存也容易碎片化。
(2)khugepaged线程合页时,容易触发页面规整甚至内存回收,该过程费时费力,容易造成sys cpu上升
(3)mmap lock本身是目前内核的一个性能瓶颈,应当避免write lock的持有,但THP合页等操作都会持有写锁,且耗时较长(数据拷贝等),容易激化mmap lock锁竞争,影响性能。
通过cmdline参数和sysfs接口设置THP模式,设置为madvise模式,指定使用大页的地址范围,内核只对指定的地址范围做THP相关操作:
cmdline参数:
transparent_hugepage=madvise
sysfs接口:
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
实践过程:
【1】Top
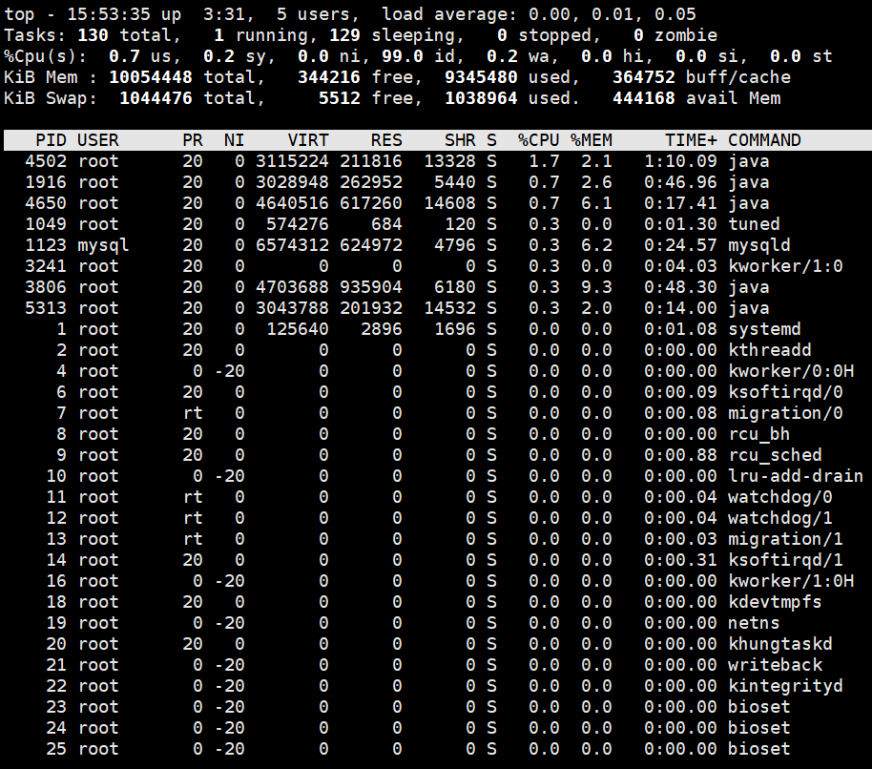
- 虚拟内存通常并不会全部分配物理内存
- 共享内存SHR并不一定是共享的,如程序的代码段、非共享的动态链接库,都算在SHR里;
【2】磁盘和文件写案例,案例一:写文件
测试命令
dd if=/dev/urandom of=/tmp/file bs=1M count=500
监控命令:vmstat 2
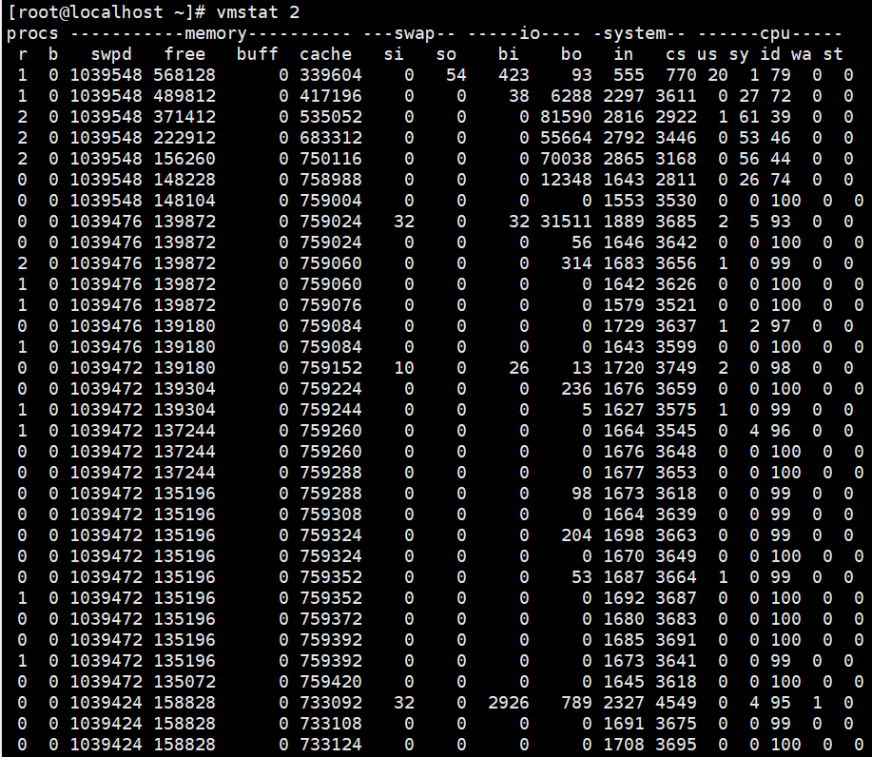
- 在Cache开始增长时,块设备I/O很少,时间增长,出现大量块设备写操作;
- 当dd命令结束时,Cache不再增长,但块设备写还需要一段时间,最终I/O写的结果加起来总共是dd要写 的500M的数据
【3】磁盘和文件写案例-案例二:写磁盘
向磁盘分区/dev/sda2写入2G数据

监控命令:vmstat 2
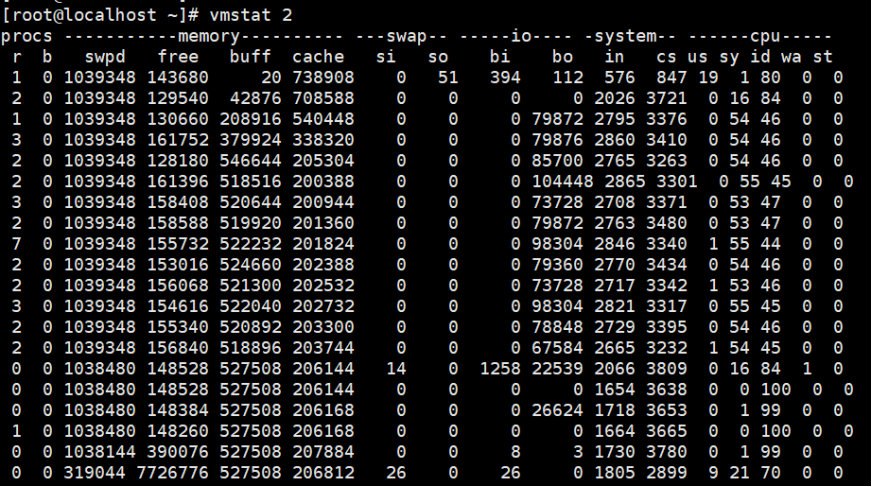
写磁盘过程中,就是bo大于0时,Buffer和Cache都在增长,但是Buffer的增长更快
【4】磁盘和文件案例–案例一,读文件
测试命令
#运行dd命令读取文件数据
dd if=/tmp/file of=/dev/null
监控:
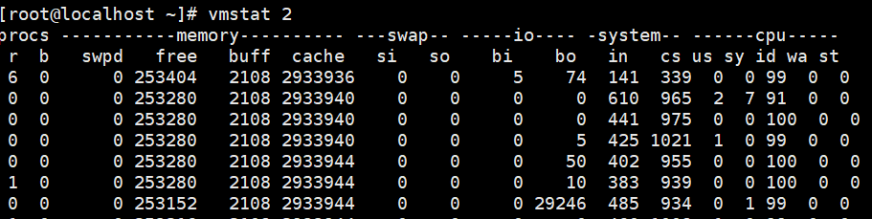
读取文件时(bi大于0),Buffer保持不变,Cache则在增长。
【5】磁盘和文件–案例二,读磁盘
测试命令
运行dd命令读取文件

监控结果:

读磁盘时(也就是bi大于0时),Buffer和Cache都是增长,但是Buffer增长更快。
CPU性能调优:
1、CPU缓存
缓存分为L1、L2、L3三种层次,层次越高,缓存容量越大,访问速度越快
2、CPU锁
多线程程序中,一个Linux内核的特殊锁,控制CPU锁的数量,减少CPU锁的竞争,提高CPU性能
3、调整linux内核参数
编辑/etc/sysctl.conf文件,增加一行参数,如:kernel.shmmax = 1073741824(表示更大的共享内存为1073741824字节),执行sysctl -p生效

4、调整I/O调度方式
I/O访问减少,系统效率也会增加。I/O调度方式有:CFQ(高IO多任务场景)、noop(IO访问时延小场景)、Deadline(IO访问时间控制场景)等。
5、系统压力测试工具
(1)模拟一个CPU使用率100%场景60秒
stress –cpu 1 –timeout 60

我的系统中是4个cpu内核,这里1个使用率100%,使用率则达到了25.9%。模拟场景结束后

恢复到0.3%。
(2)模拟I/O压力,不停地执行sync,60秒,三个CPU测试
stress -i 3 –timeout 60

测试结束后

恢复至0.3%
(3)模拟大量进程的场景,模拟8个进程
stress -c 8 –timeout 60

测试完成后恢复正常。
小结,可以先通过这三个测试过程模拟测试场景
6、CPU使用率达到100%,如何解决?
CPU节拍率
(1)节拍率
节拍率设置一般为100、250、1000等,设置为多少,那系统在每秒钟就会触发多少次时间中断。

我的本地默认是1000HZ.节拍率越大,CPU在短时间内会执行更多指令,性能可以提高,但是发热量,能耗,稳定性会降低,这个需要通过cpu性能测试去调试。
通过/proc/stat查看不同节拍率下,cpu的累积节拍数,单位是10ms,也就是不同场景下CPU时间
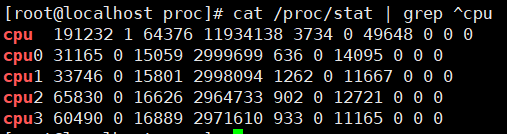
user nice system idle iowait irq softirq steal guest guest_nice
- user: CPU 时间在用户模式下的总时间(单位是时钟滴答数,即节拍数)。
- nice: CPU 时间在用户模式下以优先级较高方式运行的进程占用的时间。
- system: CPU 时间在核心模式下的总时间。
- idle: CPU 时间处于空闲状态的总时间。
- iowait: CPU 时间等待 I/O 操作完成的总时间。
- irq: CPU 时间处理硬件中断的总时间。
- softirq: CPU 时间处理软件中断的总时间。
- steal: 虚拟化环境中,其他虚拟机或者主机偷走本机 CPU 时间的总时间。
- guest: 运行虚拟 CPU 上的客户机所花费的 CPU 时间。
- guest_nice: 运行以较高优先级运行的虚拟 CPU 上的客户机所花费的 CPU 时间
CPU使用率
平均CPU使用率=1-(空间时间(new)-空间时间(old))/(总CPU时间(new)-总CPU时间(old))
pidstat 1 5命令
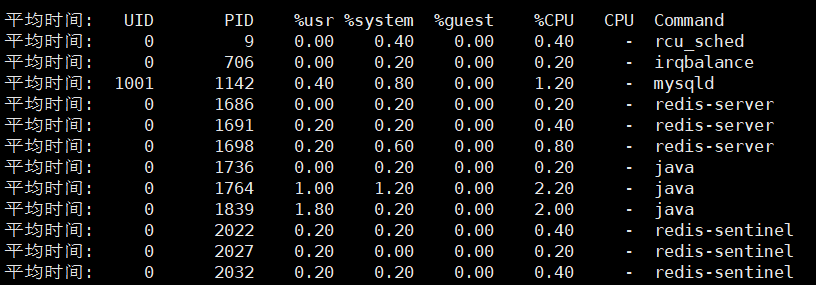
每隔1秒输出一组数据,输出5组。
CPU使用率过高如何查找相应进程,并且查到占用CPU的是代码里的哪个函数?
GDB
只能用于不在生产时使用GDB分析,因为运营GDB时会导致程序中断。
perf top
实时显示占用CPU时间片最多的函数或者指令,可以用来查看热点函数
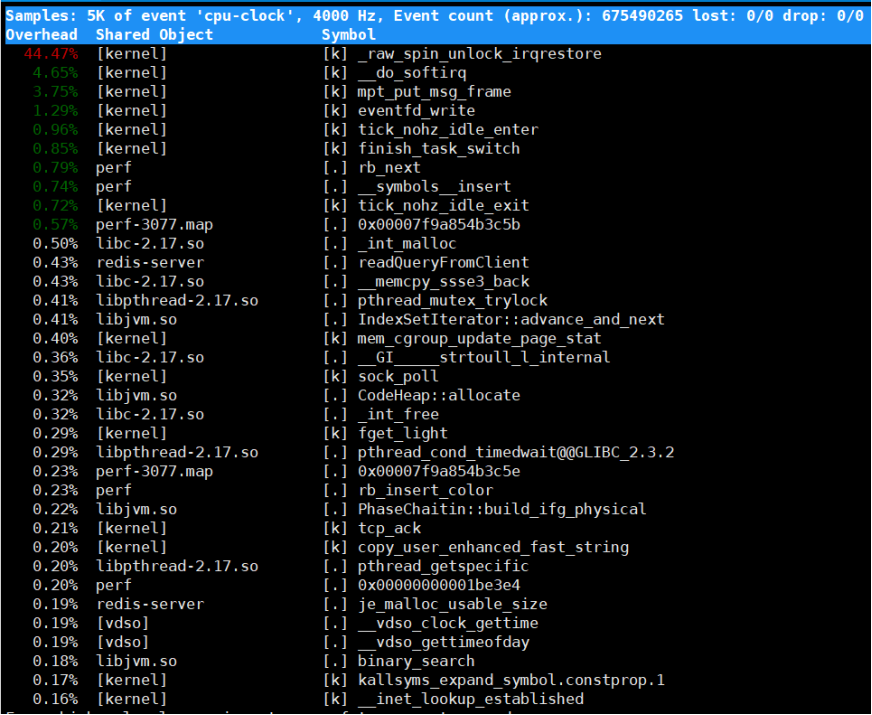
Samples(采样数)、event(事件类型)、事件总数量(Event count)
Overhead:采样数中所占比例
shared:函数或指令所在的共享对象(Dunamic Shared Object),如内核、进程名、动态链接库名、内核模块名
Object:动态共享对象的类型。[.]表示用户空间的可执行程序、或者动态链接库,而[k]则表示内核空间
Symbol:符号名,或者是函数名,未知函数名用十六进制地址表示
可以使用perf top -g 和per record -g开启调用关系采样,方便根据调用链来分析性能问题。
如:
perf top -g -p 1764
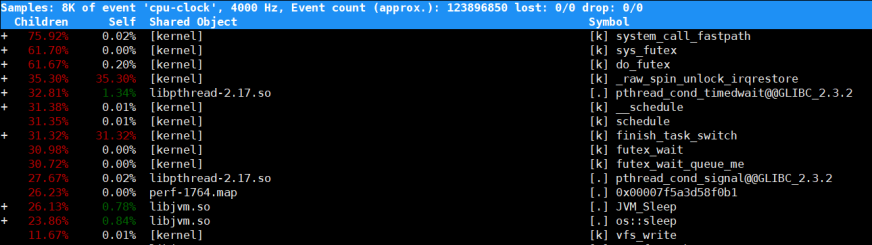
展示为:
当前函数子函数所占比例 当前函数所占比例 当前函数所属的共享对象(库) 当前函数的符号(函数名或地址)
可以通过这个命令分析当前运行程序中,哪个函数占用了大量cpu性能,再针对进程优化。
系统中出现大量不可中断进程和僵尸进程怎么办?
间隔 1 秒输出 10 组数据
[root@localhost ~]# dstat 1 10
You did not select any stats, using -cdngy by default.
–total-cpu-usage– -dsk/total- -net/total- —paging– —system–
usr sys idl wai stl| read writ| recv send| in out | int csw
0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885
0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135
0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177
0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144
0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147
0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131
0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168
0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134
可以看出,当iowait升高时,磁盘读请求很大,说明iowait的升高与磁盘的读请求有关,是磁盘的读请求导致。