一、orderby 运行机制
1.1 全字段排序
orderby 的执行流程:
1、初始化 sort_buffer,确定需要放入的字段(需要查询的字段)。
2、获取字段的值,放入 sort_buffer 中。
3、对 sort_buffer 中的数据按照指定字段做排序。
4、将排序后的结果返回给客户端。
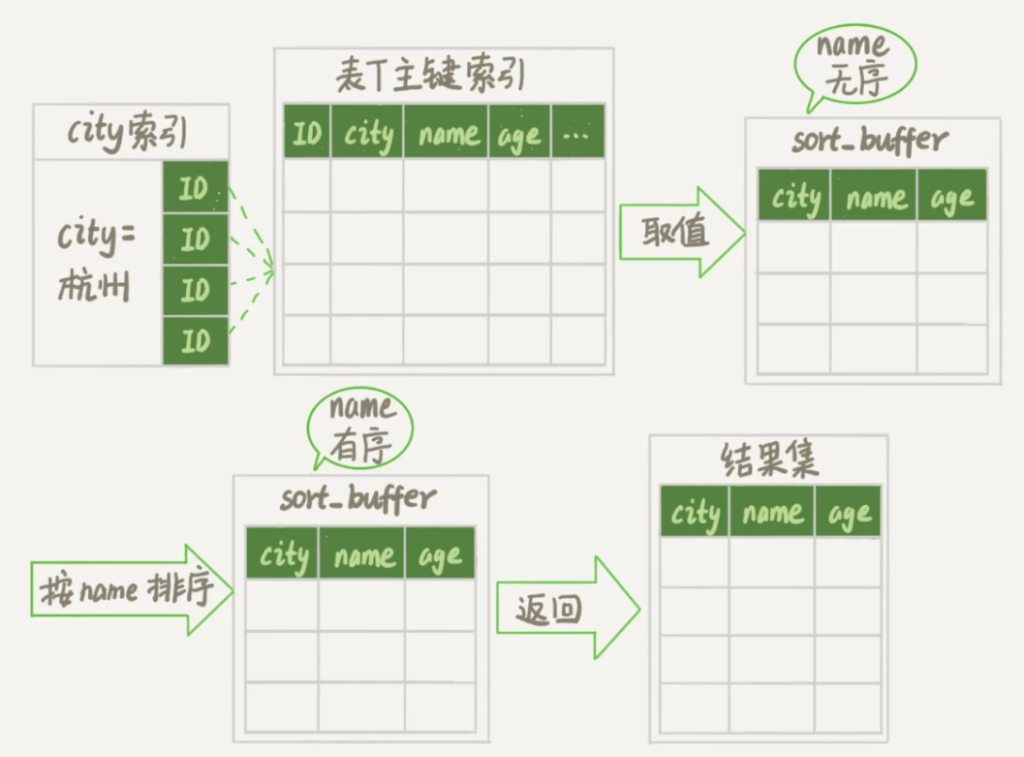
orderby 排序的位置:
排序这个动作可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。如果排序的数据量小于 sort_buffer_size,排序在内存中完成。如果排序量太大,就利用磁盘临时文件辅助排序。
sort_buffer_size:MySQL 为排序开辟的内存(sort_buffer)大小。
缺点:
一旦查询返回的字段很多,那么 sort_buffer 里要放的字段数太多,会导致内存里能同时放下的行数很少,要分成很多个临时文件,排序性能很差。
1.2 rowid 排序
orderby 的执行流程:
1、初始化 sort_buffer,确定需要放入的字段(指定的排序字段和id)。
2、获取字段的值,放入 sort_buffer 中。
3、对 sort_buffer 中的数据按照指定字段做排序。
4、按照 id 的值和排序结果回到原表取出查询字段的值返回给客户端。
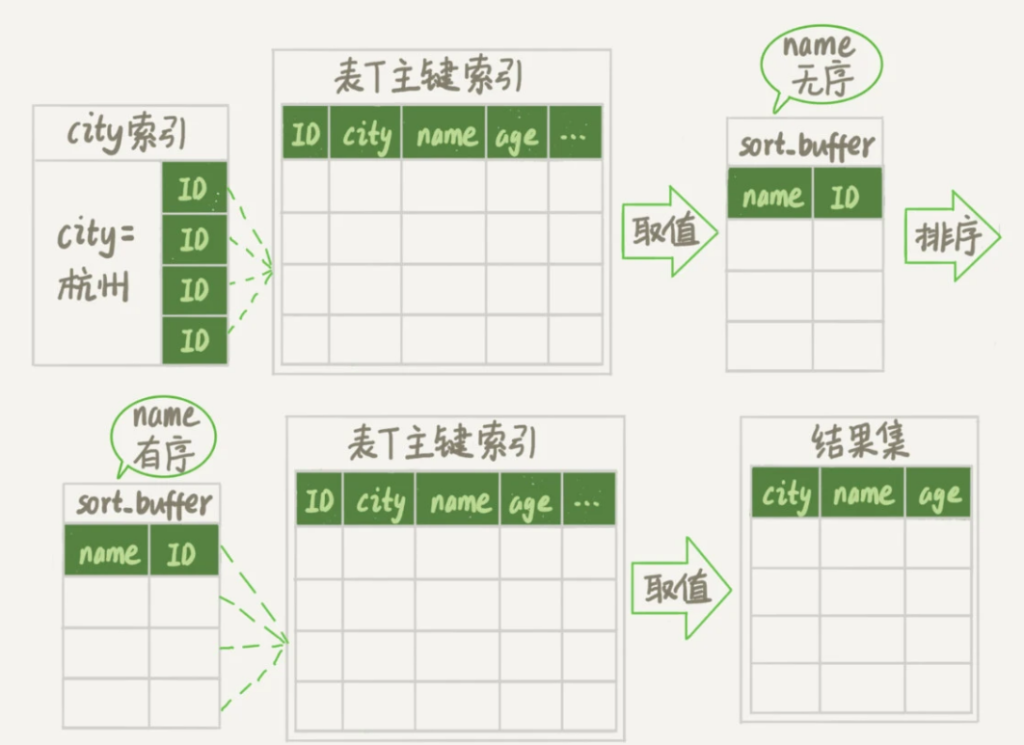
max_length_for_sort_data:MySQL 中专门控制用于排序的行数据的长度的一个参数,当单行的长度超过这个值,MySQL 就认为单行太大,使用 rowid 排序,否则使用全字段排序。
对于InnoDB表来说,执行全字段排序会减少磁盘访问,因此会被优先选择。
对于内存表,回表过程只是简单地根据数据行的位置,直接访问内存得到数据,根本不会导致多访问磁盘
二、影响 SQL 语句性能的点
2.1 条件字段函数操作
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
不过优化器在个问题上确实有“偷懒”行为,即使是对于不改变有序性的函数,也不会考虑使用索引。
即对索引字段做函数操作,优化器会放弃走树搜索功能。
2.2 隐式类型转换
当使用的比较条件与索引字段属性不一致时,会调用函数对字段做隐式转换,从而导致索引失效。
2.3 隐式字符编码转换
当使用两张不同编码的表的索引进行比较时,会调用函数进行隐式字符编码转换,从而导致索引失效。
注:索引字段进行函数操作时不能走索引,但是索引字段作为参数进行函数操作时可以走索引。
# tradelog为utf8mb4# trade_detail为utf8# tradeid是两张表的索引字段# 索引字段进行函数操作,不走索引select d.* from tradelog l , trade_detail d where d.tradeid=tradeid and l.id=2;# 索引字段作为参数进行函数操作,走索引select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2; |
2.4 查询语句慢的原因
- 查询长时间不返回,一般是表被锁住了,可以使用 show processlist 命令查看当前语句的状态。
- 等 MDL 锁,命令显示 Waiting for table metadata lock。
- 等 flush,命令显示 Waiting for table flush。
- 等行锁,通过 sys.innodb_lock_waits 表可查。
- 查询慢,排查方法:分析慢查询日志,可选择性对日志中的语句进行 explain 分析。
# 查看慢查询配置show variables like 'slow_query%';show variables like 'long_query%';# 打开慢查询日志set global slow_query_log=ON;# 调节慢查询时间上线set long_query_time=[秒]; |
三、幻读
InnoDB 的默认事务隔离级别是可重复读,可重复读的条件下,一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没看到的行,称之为幻读。
幻读仅在当前读下才会出现,且仅专指“新插入的行”。
注 :在可重复读的隔离级别下,普通的查询是快照读,不会看到别的事务插入的数据。当前读,读取的是数据的最新版本,需要获取到对应记录的锁。
3.1 幻读带来的问题
- 破坏锁的语义。
- 破坏数据的一致性。
- 会影响新插入的记录。
3.2 如何解决幻读?
为了解决幻读,InnoDB引入了间隙锁。
间隙锁锁的是两个值之间的空隙,通过锁索引叶子节点的 next 指针实现,间隙锁间无冲突,即可以对一个间隙上多把间隙锁,但往间隙中插入记录会冲突。
执行当前读的时候,不仅会给数据库中的行加上行锁,并且给行两边的间隙加上间隙锁,这样就确保了无法插入新的记录。
间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。
间隙锁的问题:
- 间隙锁的引入会导致同样的语句锁住更大的范围,会影响并发度。
- 两个 session 同时在同一个区间锁上间隙锁,且两个 session 同时往这个区间内插入值会导致互相等待,进入思索。
注 1:间隙锁只有在可重复读隔离级别下才生效。
注 2:在 InnoDB 的基础设定中,锁是加在索引上的。
3.3 加锁规则
可重复读下的加锁规则:
可分为两个原则、两个优化、一个 bug
两原则:
- 加锁的基本单位是 next-key lock。
- 查找过程中访问到的对象才会加锁。
两优化:
- 索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
- 索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
在当前读带 limit 时,满足条件后,不会再查找下一个对象,没有查找到对象,后面的数据就不会上锁。
建议:在删除数据时尽量加 limit,不仅可以控制删除数据的条数,还可以减小锁的范围。
读提交下的加锁规则:
语句执行过程中加上的行锁,在语句执行完成后,就把“不满足条件的行”上的行锁释放掉,不需要等到事务提交。
也就是说,读提交隔离级别下,锁的范围更小、时间更短。
四、临时提高 MySQL 的性能
4.1 短连接风暴
问题:采用短连接的方式连接数据库,业务高峰期,连接数暴涨。
场景:
- 数据库有 max_connections 参数,控制 MySQL 实例同时存在的连接数上限,超过这个值就会拒绝连接,返回报错,从业务角度来看就是数据库不可用了。
- 假如调大这个参数,系统的负载会增大,大量的资源耗费在权限验证等逻辑上,反而已经连接的线程拿不到 CPU 资源去执行业务的 SQL 请求。
解决办法:
- 先处理掉占着连接不工作的线程。 实现方法:可以通过 kill connection 或者设置 wait_timeout 实现。 问题:这个方法会存在误删有用线程的问题,导致应用侧延迟报错。
- 减少连接过程中的消耗。 实现方法:让数据库跳过权限验证阶段,重启数据库,使用 -skip-grant-tables 参数启动,整个 MySQL 会跳过所有的权限验证阶段。 问题:数据库有很大的被入侵风险。
注:在 MySQL 8.0 版本里,启动 -skip-grant-tables 参数会默认同时打开 –skip-networking 参数,表示只能被本地的客户端连接。
4.2 慢查询性能问题
在 MySQL 中,会引发性能问题的慢查询,大体有以下三种可能:
- 索引没设计好。
- SQL 语句没写好。
- MySQL 选择错了索引。
问题一:索引没设计好。
解决办法:紧急创建索引。MySQL 5.6 版本以后,创建索引支持 Online DDL,最高效的版本是直接执行 alter table 语句。
紧急情况下,最高效的方案是能够在备库先执行,假如现在一主一备,大概流程如下:
- 在备库 B 上执行 set sql_log_bin=off,也就是不写 binlog,然后执行 alter table 语句加上索引。
- 执行主备切换。
- 这时候主库是 B,备库是 A。在 A 上执行 set sql_log_bin=off,然后执行 alter table 语句加上索引。
平时做变更时,应该考虑类似 gh-ost 这样的方案。
问题二:SQL 语句没写正确。
解决办法:
# 例子:假如语句错误写成了 select * from t where id + 1 = 10000,可以通过语句重写查询insert into query_rewrite.rewrite_rules(pattern, replacement, pattern_database) values ("select * from t where id + 1 = ?", "select * from t where id = ? - 1", "db1");# 这个存储过程让插入的新规则生效,也就是“查询重写”call query_rewrite.flush_rewrite_rules(); |
问题三:MySQL 选错了索引。
解决方案:使用查询重写功能给原来的语句加上 force index。
慢查询的问题实际上都应该在上线前发现问题。
- 上线前,在测试环境,把慢查询日志(slow log)打开,并且把 long_query_time 设置成 0,确保每个语句都会被记录入慢查询日志;
- 在测试表里插入模拟线上的数据,做一遍回归测试;
- 观察慢查询日志里每类语句的输出,特别留意 Rows_examined 字段是否与预期一致。
如果新增的SQL语句不多,手动跑一下就可以。
而如果是新项目的话,或者是修改了原有项目的表结构设计,全量回归测试都是必要的,这时候,需要工具帮助检查所有的SQL语句的返回结果。
开源工具 pt-query-digest(https://www.percona.com/doc/percona-toolkit/3.0/pt-query-digest.html)。
4.3 QPS 突增
问题:由于业务突然出现高峰,或者应用程序 bug,导致某个语句的 QPS 突然暴涨,可能会导致 MySQL 压力过大,影响服务。
场景:
- 由全新业务的 bug 导致。 解决办法:假设 DB 运维比较规范,白名单一个个加的。这种情况下如果能确定业务方会下掉这个功能,可以从数据库端把白名单处理掉。
- 新功能使用的是单独的数据库用户。 解决办法:使用管理员账号把这个用户删掉,断开现有连接。
- 新增功能与主题功能部署在一起的。 解决办法:使用查询重写功能,把压力最大的 SQL 语句直接重写成 select 1 返回。
方案 3 风险很高,是用来止血的,这个应该是优先级最低的方案,可能存在的问题:
- 如果别的功能用到了这个 SQL 语句模板,可能会误伤。
- 很多业务并不是靠一个语句完成逻辑的,如果单独把这个语句以此返回,可能会导致后面的业务逻辑一起失败。
方案 1 和 2 都要依赖于规范的运维体系:虚拟化、白名单机制、业务账号分离。